I was approached by a client to research the concept of 20% time for engineers, and they graciously agreed to let me share my results. Because this work was tailored to the needs of a specific client, it may have gaps or assumptions that make it a bad 101 post, but in the expectation that it is more useful than not publishing at all, I would like to share it (with client permission).
Side project time, popularized as 20% time at Google, is a policy that allows employees to spend a set percentage of their time on a project of their choice, rather than one directed by management. In practice this can mean a lot of different things, ranging from “spend 20% of your time on whatever you want” to “sure, spend all the free time you want generating more IP for us, as long as your main project is completely unaffected” (often referred to as 120% time) to “theoretically you’re free to do whatever, but we’ve imposed so many restrictions that this means nothing”. I did a 4-hour survey to get a sense of what implementations were available and how they felt for workers.
A frustration here is that almost all of what I could find via Google searches were puff-pieces, anti-puff-pieces, and employees complaining on social media (and one academic article). The single best article I found came not through a Google search, but because I played D&D with the author 15 years ago and she saw me talking about this on Facebook. She can’t be the only one writing about 20% time in a thoughtful way and I’m mad that that writing has been crowded out by work that is, at best, repetitive, and at worst actively misleading.
There are enough anecdotal reports that I believe 20% time exists and is used to good effect by some employees at some companies (including Google) some of the time. The dearth of easily findable information on specific implementations, managerial approaches, trade-offs, etc, makes me downgrade my estimate of how often that happens, vs 20% time being a legible signal of an underlying attitude towards autonomy, or a dubious recruitment tool. I see a real market gap for someone to explain how to do 20% time well at companies of different sizes and product types.
But in the meantime, here’s the summary I gave my client. Reminder: this was originally intended for a high-context conversation with someone who was paying me by the hour, and as such is choppier, less nuanced, and has different emphases than ideal for a public blog post.
My full notes are available here.
- To the extent it’s measured, utilization appears to be low, so the policy doesn’t cost very much.
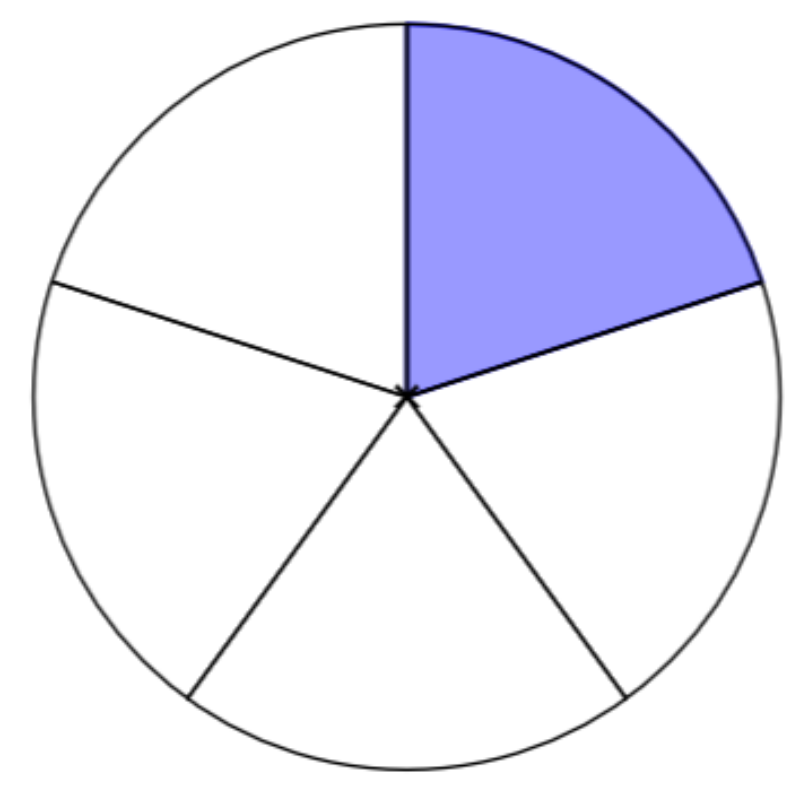
- In 2015, a Google HR exec estimated utilization at 10% (meaning it took 2% of all employees’ time).
- In 2009, 12 months after Atlassian introduced 20% time, recorded utilization was at 5% (meaning employees were measured to spend 1.1% of their time on it) and estimated actual utilization was <=15% (Notably, nobody complains that Atlassian 20% is fake, and I confirmed with a recently departed employee that it was still around as of 2020).
- Interaction with management and evaluation is key. A good compromise is to let people spend up to N hours on a project, and require a check-in with management beyond that.
- Googlers consistently (although not universally) complained on social media that even when 20% time was officially approved, you’d be a fool to use it if you wanted a promotion or raises.
- However a manager at a less famous company indicated this hadn’t been a problem for them, and that people who approached perf the way everyone does at Google would be doomed anyway. So it looks like you can get out of this with culture.
- An approval process is the kiss of death for a feeling of autonomy, but letting employees work on garbage for 6 months and then holding it against them at review time hurts too.
- Atlassian requires no approval to start, 3 uninvolved colleagues to vouch for a project to go beyond 5 days, and founder approval at 10 days. This seems to be working okay for them (but see the “costs” section below).
- Costs of 20% time:
- Time cost appears to be quite low (<5% of employee time, some of which couldn’t have been spent on core work anyway)
- Morale effects can backfire: Sometimes devs make tools or projects that are genuinely useful, but not useful enough to justify expanding or sometimes even maintaining them. This leads to telling developers they must give up on a project they value and enjoyed (bad for their morale) or an abundance of tools that developers value but are too buggy to really rely on (bad for other people’s morale). This was specifically called out as a problem at Atlassian.
- Employees on small teams are less likely to feel able to take 20% time, because they see the burden of core work shifting to their co-workers. But being on a small team already increases autonomy, so that may not matter.
- Benefits of 20% time:
- New products. This appears to work well for companies that make the kind of products software developers are naturally interested in, but not otherwise.
- The gain in autonomy generally causes the improvements in morale and thus productivity that you’d expect (unless it backfires), but no one has quantified them.
- Builds slack into the dev pipeline, such that emergencies can be handled without affecting customers.
- Lets employees try out new teams before jumping ship entirely.
- Builds cross-team connections that pay off in a number of ways, including testing new teams.
- Gives developers a valve to overrule bug fixes and feature requests that their boss rejected from the official roadmap.
- There are many things to do with 20% time besides new products.
- Small internal tools, QOL improvements, etc (but see “costs”).
- Learning, which can mean classes, playing with new tools, etc.
- Decreasing technical debt.
- Non-technical projects, e.g. charity drives.
- Other notes:
- One person suggested 20% time worked better at Google when it hired dramatically overqualified weirdos to work on mundane tech, and as they started hiring people more suited to the task with less burning desire to be working on something else, utilization and results decreased.
- 20% or even 120% time has outsized returns for industries that have very high capital costs but minimal marginal costs, such that employees couldn’t do them at home. This was a big deal at 3M (a chemical company) and, for the right kind of nerd, big data.
Thanks to the anonymous client for commissioning this research and allowing me to share it, and my Patreon patrons for funding my writing it up for public consumption.