dynomight recently wrote an article calling for bloggers to state publicly whether and how they use AI. Here are ways I currently use AI in ways that might show up on this blog:
I use AI to find papers and explain bits I don’t understand (generally vocabulary), and generally tutor me.
I sometimes ask AI to find flaws in papers. I verify the flaws before citing them and don’t consider a paper flawless just because AI didn’t find anything.
When I’m stuck I’ll ask AI to generate many ideas to unstick me. This could be anything from word choice to themes for a concluding paragraph. I don’t copy/paste beyond a word or two, the point is not to generate the answer but to unstick my brain.
I use AI for feedback much the way I use friends or editors.
I’ve coded tools to do data analysis, although I’m not sure anything from them has made it to print yet.
I wrote this in 4 minutes so I may come back later with edits as new uses occur to me.
EDIT 10m later: I explain my ideas to AI with a prompt to ask questions as if it is trying to understanding.
Then this month I published On the origin of continents at Works in Progress, about the simultaneous, semi-independent dual discoveries of plate tectonics.
How much do cows suffer in the production of milk? I can’t answer that; understanding animal experience is hard. But I can at least provide some facts about the conditions dairy cows live in, which might be useful to you in making your own assessment. My biggest conclusion is that cows made better choices than chickens by making their misery financially costly to farmers.
Life Cycle
The life of a dairy cow starts as a calf. She is typically separated from her mother a few hours to a few days after birth and, to reduce disease risk, held in isolation. Cutting edge farms will sometimes house calves in pairs. This isolation is clearly stressful for a baby herd mammal and her mother, but I didn’t find any quantification of that stress that I trusted.
Calves will be bottlefed until weaning at 6-8 weeks (4-6 months earlier than beef calves). After weaning and vaccinations they can be introduced into a herd. At large farms (where most cows live), they will move in and out of different herds through their lifecycle. This is more stressful than being embedded with your friends for life, but again, I found no trustworthy quantification.
Heifers (unbred dairy cows) are first bred at 12-15 months, and calve 9 months later. After this, they will be on a ~yearly cycle of pregnancy, birth, and lactation (they will lactate through most of pregnancy). They will typically have 3 pregnancies before their milk production decreases and they are killed. An advantage cows have that egg chickens lack is that stress immediately and measurably decreases their economic productivity. This makes Cow Comfort big business, although if we can’t solve the sadist problem in nursing homes I don’t see how we can assume it’s solved in cows.
On average, ⅓ of dairy calves will go on to be dairy cows (herd size is constant or slightly shrinking in America despite increased demand, because productivity is increasing faster). ~2% will be raised for veal, some unknown percentage will be killed immediately, and most will be raised to be slaughtered for meat as adults. Early childhood stress probably hurts future meat cattle’s economic productivity as well, but because they switch farms while young, the farm raising them after birth has neither knowledge nor the incentive to minimize their stress.
How much time do dairy cows spend outside?
My guess is that cows feel happiest in open pastures surrounded by their friends and sunshine and fresh grass. My judgement is already suspect, because one study showed cows prefer twilight to bright sunshine. But the same study showed they did really like to go outside, so let’s continue on that assumption.
It’s important to note that outside does not necessarily mean idyllic pasture. It can also mean a concrete exercise yard or feedlot. And no modern American dairy cow lives on grass alone, even if they live on a pasture. Their staggering milk production requires more calories than they could possibly get through grass alone.
Conventionally raised cows are not required to spend any time outside. Organic-certified cows must have at least 120 days of pasture time per year and year-round outdoor access of some kind. In practice, California cows get considerably more time outside than Wisconsin or New York cows, for the obvious reason.
The most recent data said that only 5% of lactating cows (which is almost all of them- cows lactate through most of their pregnancies) have access to pasture to graze. That paper was published in 2017 but it might be using older data. Given the wording it’s possible that the cows are given access during times without grass growth, but why would farmers do that? A 2007 study found that only 13% of cows had no outdoor access at all, and half had access to a pasture at least some of the time. So it looks like outdoor access is getting worse
By humaneness standard
You can buy milk with little stickers printed on it advertising a humaneness standard. What do these tell you about the cows’ outdoor life?
American Humane Certified: does not require outdoor access of any kind for cows
Certified Humane: cows must have access to outdoors, but not necessarily pasture.
Organic: cows must graze pasture throughout the grazing season for their geographic location, derive at least 30% of dry matter intake from pasture, for a minimum of 120 days per year. I consider organic kind of bullshit, so I was surprised that it was such a strong demand for dairy cows.
Global Animal Partnership 5-step
Step 4+: on pasture >=120 days/year
Step 5+: continuous pasture
Animal Welfare Approved / A Greener World: requires continuous pasture living for cows except during actual fires. Emergencies exceeding 28 days require some sort of plan. I was unable to find any drinking milk with this label in the bay area, but there are a few stores with AWA cheese.
Strauss Farms claims to meet organic standards and never use antibiotics. I have a pet theory that removing the option for antibiotics forces farms to treat animals better, because bad conditions engender disease and without the quick fix of antibiotics that can get very expensive.
When indoors, how confined are dairy cows?
Free stall barns are “standard” (personal communication) in the US. These barns lower their walls in good weather, giving cows access to fresh air but not any more space. They average 100 sq ft per cow, including both personal stalls and common areas. Is that enough? I have no idea.
Some humaneness standards ban tie stalls, but they’re not common in the US even with conventional cows.
What is the disease load of dairy cows?
Disease and injury are both common sources of misery and canaries for mistreatment. So how sick are dairy cows?
Note that this graph means : n% of cows experience that issue in a lactation cycle (almost a year), not that n% of cows are experiencing this issue at any given time, which is how I initially read it.
Mastitis is more common that the other issues combined, so I dug in further.
A 2022 study of Wisconsin herds found 25% of cows in a lactation cycle got clinical mastitis (so ~once per year).
Mastitis requires throwing out milk and spreads easily, so farmers are pretty quick to cull chronically infected cows. 25% of culls are for mastitis or other udder problems.
A 2014 paper found almost the exact same incidence
Some larger percent have subclinical mastitis.
In humans, mastitis is quite painful, but many women choose to go through it in order to have kids. OTOH, they get to keep those kids.
I didn’t dig into this but New Zealand cows reportedly have much lower incidence of mastitis, so pasture raising or less intensive cultivation is probably beneficial.
Euthanasia
The time between experiencing enough suffering to justify euthanasia and the actual euthanasia is probably the most intense physical suffering a cow will experience. It would be useful to know how long that delay is. Unfortunately no one has looked.
We can try to make some guesses based on the ratio of unassisted deaths to euthanasia. In 2013 the data on deaths is as follows (note: they’re using the technical definition of cows, meaning they’ve had at least one pregnancy):
Most notable: calves are 2x as likely to die unassisted in small farms than large, but have ~the same likelihood of euthanization. For adult cows the gap is reversed and much smaller. It seems really unlikely those calves all had painless heart attacks, so we can assume days if not weeks or months of suffering.
How much socialization do dairy cows get?
Herd animals feel better in herds. How much do dairy cows get to indulge that instinct?
As of 2011, 80% of dairy farms used individual housing for newborn calves, to limit disease spread. This is undoubtedly stressful to the calf, but I don’t trust any of the attempts to quantify exactly how stressful. Disease prevention is a serious issue, since as is ¼ of calves get Bovine Respiratory Disease (in CA).
Pair housing of calves is economically productive and so probably gaining in prevalence.
Dairy cows spend the bulk of their life in large herds. However:
They’re isolated when sick and shortly before giving birth
They are frequently moved between social groups, which is stressful. That stress is economically impactful and so selected against
OTOH this paper found moving with a friend (as opposed to alone) changed behavior but not cortisol levels, so either friends don’t help or moving isn’t that stressful.
They claim significant subgroup results for cows with only one pregnancy. In the absence of a reason for these cows to feel differently, I assume this is a statistical blip.
The Fate of Calves
Milk production also creates a lot of by-catch in the form of newborns that aren’t needed in the dairy herd. Their lives should be considered part of the consequences of dairy. So what are their lives like?
Abby Shalek-Briski reports on new sex-sorting technology that allows farmers to produce exactly as many female dairy calves as they need to maintain their herd, and use the rest of the pregnancy slots to produce dairy-beef hybrid males who are raised to adulthood and slaughtered for meat. I didn’t research this, but my impression is that beef cattle have pretty good lives.
In a private discussion, Abby said 18% of calves in the herds she works with are hybrids destined for non-veal meat, but there’s no nationwide data collection to nail it down further.
~30% of births go on to be dairy cattle
Average 3 pregnancies/cow and American herds are stable or shrinking due to increased productivity.
Last summer I got nerdsniped by evangelical christianity, and in particular church planting, the domestic missionary system used by nondenominational churches to resolve the conflict between an abhorrence of hierarchy and a drive to spread the Word. The system was so different from what I expected from religion; I wanted to understand the frame that made it make sense to its members. What I found were values and mechanisms nearly identical to Silicon Valley’s start-up/venture capital culture along with a healthy dose of American “don’t tell me what I can’t do” in ways that warm my libertarian heart.
That post is one of my favorites of anything I’ve written, in part because it had head and shoulders the best comments. There were enoughcompliments to make me feel good about what I’d learned, and enoughcriticisms to teach me more. For the first time, I am compelled to create a post solely to highlight comments on a previous post.
This isn’t the only sequel in the works. My biggest regret from that post is that I gave only a few paragraphs to the experience of being a pastor’s wife. I’m a sucker for “this system is simultaneously very different from what I know and yet running on similar human hardware, in ways that help me understand the hardware”, it’s what attracted me to church planting in the first place, and understanding the mechanisms and rewards of pastor’s-wifing feels like it will offer even more insight. I’ve had this on my list for a while, but when Asterisk Magazine announced their upcoming issue was themed around Work, it moved to the top.
My second biggest regret from the original post was that I relied 100% on published material, with no original interviews. I want to fix that too. If you or someone you know has insight into being a pastoral spouse, I would love to talk to you/them. You can reach me at elizabeth@acesounderglass.com.
What I Got Wrong
My post focused on non-denominational churches, so it makes sense that many of the corrections pertained to denominational evangelicals. To my surprise, “evangelical denomination” is not a synonym for “evangelizing churches.” Lots of churches in evangelical denominations do not emphasize recruitment. They don’t send out new churches and they don’t encourage members to recruit either.
When the church planters I listened to talk about non-planting churches (which are a supermajority- maybe 90%?), it’s with something of a sneer. They don’t view these churches as choosing a different path, but as failing at the one true path of bringing in new souls to shake Jesus’s hand. The planters love non-planters in their failure… but they are praying for the failures to see the light some day.
Multiple people mentioned that, in their part of the evangelosphere, seminary degrees were mandatory. If not a full seminary degree at time of founding, then at least an online certificate within 4 years.
On the other hand, mruwnik reports that in his childhood denomination (where his parents were international missionaries), seminary degrees were viewed with suspicion. Not forbidden by any means, but more negative than positive.
In the previous post I described free grace theology: the idea that salvation requires only the profession of faith, and that good deeds are not only not necessary for salvation, they aren’t even evidence of faith. I represented this as the standard evangelical view, but Pof pushed back that this is an American view. In Europe, FGT is almost unknown.
This was easy to check. The Free Grace Alliance has a map of participating churches, and all of its members save 6 are in the US. Europe only has “grace friendly” churches.
There are evangelizing organizations that focus on spreading free grace theology in Europe, but they’reboth based in the US.
Salvation without evidence is an area of conflict within the US, even within the evangelical community. The self-identity of the opposition is lordship salvation, which teaches that if you believe in Christ it will show up in your actions. They decry free grace as easy–believism. The free grace people call the lordship salvation people fruit inspectors (from the verse “A tree is recognized by its fruit…”).
Free grace theology is also very new, by religious standards. This article dates it to not quite 50 years old, which would put it right alongside the evangelical boom of the 80s.
What I Got Right
One of my north stars when writing the piece was portraying evangelical Christians in a way they would recognize and find respectful. Not that I would lie to make them look better, but I wanted to present “What are their terms for success?” rather than “How are they doing by my terms for success?” I’m delighted that multiple evangelicals spontaneously praised my understanding, even when they had addenda.
The link between venture capital and evangelical Christianity was closer than I thought. They’re not just analogous; they deliberately cross-pollinate. GWD took a seminary course that repeatedly referenced Barbarians to Bureaucrats, a book on the corporate lifecycle. Solhando points to start-up founders reading The Purpose Driven Church because it’s a “well known manual for building startup culture, attracting dedicated employees, and raising capital”.
Generally people agreed at the factors I pointed to rewarding narcissism, although of course if you know lots of pastors based through their work instead of by how much mainstream attention they capture, they represent a lower proportion of pastors you know.
When I talked to people about the church planting post, they always wanted to know what got me interested in church planting. The short answer is that I listened to the excellent Rise and Fall of Mars Hill Church podcast, which presents a case study of the harms and benefits of a church plant in order to ask what systems made this possible. But the longer answer is that I spend a lot of time around scared, neurotic people, and it was soothing to listen to voices who were so sure that they were doing what they should be doing and everything would ultimately work out. Even if I disagreed with them on the facts that make them so confident, it was a nice vibe to visit.
My current frame on the spousal sequel is “what a specific job, what can its specificities teach us about work in general?”. But I didn’t see the conclusion to the original post coming at all, so I want to leave room to be surprised. I’m sure being a pastor’s wife is work, but is job even the right frame? If you have information on this I would love to talk to you. You can reach me at elizabeth@acesounderglass.com, and I’m happy to answer questions about myself or the project before you decide.
Thanks
Thanks to everyone who read the post and especially those who wrote such edifying comments.
Thanks to the CoFoundation fellowship for their financial support of my work.
Thanks to Progress Studies Blog Building Initiative for beta readers and editing support.
When it comes to clothes, I live at the “low cost/low time/low quality” end of the pareto frontier. But the bay area had a sudden attack of weather this December, and the cheap sweaters on Amazon get that way by being made of single-ply toilet paper. It became clear I would need to spend actual money to stay warm, but spending money would not be sufficient without knowledge.
I used to trade money for time by buying at thrift stores. Unfortunately the efficient market has come for clothing, in the form of resellers who stalk Goodwill and remove everything priced below the pareto frontier to resell online, where you can’t try them on before buying. Goodwill has also gotten better about assessing their prices, and will no longer treat new cashmere and ratty fleece as the same category.
But the market has only become efficient in the sense of removing easy bargains. It is still trivial to pay a lot of money for shitty clothes. So I turned to reddit and shoggoths, to learn about clothing quality and where the bargains are. This is what I learned. It’s from the POV of a woman buying sweaters and coats, but I expect a lot of the information to be generally applicable.
General money saving tricks
When shopping online, put an item in your cart, checkout enough to give them your email address, but don’t confirm the purchase. You will almost always get a reminder email with a discount. If this doesn’t work the shop is either very high end, or Amazon. It sometimes works with individual sellers on platforms like ebay and etsy. . You can use the wait as a cooling off period where you decide if you really want something.
Most sales are fake. Real sales happen at the end of the season, when whatever you buy won’t be useful for another 9 months, if you have the misfortune to live somewhere with weather. Saving money through sales is like persistence hunting, which I find boring and stressful so I didn’t look into this much. But if you prefer it to thriting, I’m sure reddit will explain how to optimize.
Every store will offer you a coupon the second you load the site. They don’t want much, just your email address. I ignore this, and then if I decide to buy something I revisit the site in incognito mode to get the discount
Discounters
I briefly thought that even if proper thrift stores no longer worked, discounters like Marshall’s did. Officially these work by buying overstock from proper stores and reselling it at markdown, so if you don’t care about being behind trend it’s a big leap forward in the cost-quality trade off. Unfortunately, this is mostly a lie. Marshalls and TJ Maxx primarily sell items that were produced with the intention to be sold at their store, either under some brand they made up or licensing a luxury brand while not replicating the brand’s quality (legal bootlegs). Ross Dress for Less does this less but still a lot.
You can spot this at Marshall’s by looking at the ID number on the tag- ending in 1 means it was produced for Marshall’s, 2 means genuine overstock. You can also use the RN number on the sewn-in tag to check the manufacturer. My expensive-by-my-standards winter coat had every appearance of being genuine overstock, down to a tag from another store listing a price 3 times Marshall’s price, but turned out to be bootleg.
Every discounter lists a “comparison price” next to their price on their tag. It is completely made up, which is why it’s surprising that they often assign themselves a discount of < 50%. You could tell any lie you wanted, Marshall’s. Why are you holding yourself back?
Online Thrift
This is where all the good items you used to find at goodwill went- ebay, poshmark, thredup. ThredUp was amazing when it was in the “VC free money” stage, but their return policy tightened up and it’s now merely okay. Poshmark is aimed at designer goods. Ebay is like you remember, except Buy It Now is dominant and actual auctions are rare.
In addition to being more expensive than old school Goodwill, online shopping means you’re dependent on a few photos, often poorly lit, and you can no longer try items on for free. So this works best if it’s a forgiving item or you know a brand’s fit works for you. Heavy coats are almost the ideal objects to shop online- forgiving of fit, very expensive new but low resale.
Thrifting is fun for me in a way that timing sales isn’t. Whether it’s worth the time for you depends on how fun it is and your time/money exchange rate. Many sellers do allow returns for a fee, but I haven’t tested the tolerances for it (I’ve tested Amazon’s returns pretty thoroughly and their tolerance is infinite).
In addition to “save an item and wait”, resale platforms often offer the ability to proactively offer a lower price. My success rate in asking for severe discounts is maybe 10%, but it was the first time I tried so it feels higher.
Quality
I started with two methods for assessing brand quality: ask reddit and ask claude (who is mostly asking reddit). At any amount of money I could conceivably be willing to spend, there is always someone going “that stitching is so low quality it will murder your puppy”. Luckily there are many redditors who have the concept of a pareto frontier.
If you can touch the garment, you can check the quality yourself. People are surprisingly good at this intuitively, but a few things to look for are:
Fabric type. the better the fabric, the more likely they did other things right. Make sure you’re reading the fabric tag- I’ve seen items with 3% cashmere content advertised as cashmere
In general natural fibers are considered better and more expensive. My impression is that synthetic fabrics are actually pretty good now, but natural fibers are still associated with higher quality in areas like stitching and design.
Fabric thickness- higher is better
Loose threads
Is there puckering around the seams?
Is the stitching straight?
I only checked a handful of youtube reviewers, but my favorite is Jennifer Wang, who seemed properly autistic about clothing quality and understanding that there are multiple places on the pareto frontier one might choose to occupy (or alternately, has been bought off by Uniqlo, who she praises a lot as good-for-the-cost). She has this overview video, but consider watching a few brand comparisons to see it in action.
Brands
There are a lot of brands reddit thinks used to be good but have gone downhill (without corresponding drops in price). I expect this is a mix of genuine change from companies spending down brand capital and survivorship bias on older sweaters. GAP is the rare brand that people consider to be improving right now.
Brands that were frequently listed as on the pareto frontier for sweaters: Quince, Uniqlo, Naadam, Eileen Fisher, Johnstons of Elgin, William Lockie, J. Crew, Patagonia, Neiman Marcus, Lands End, Nordstroms, Everlane
Wool facts
Wool is annoying to wash. This is fine for an item of clothing I always wear over something else and by definition don’t need if I’m sweating, but I really side-eye cashmere t-shirts.
Wool’s advantage over fleece is that it is breathable, and thus is comfortable over a wider range of temperatures. If you are moving you want wool, because it allows heat to dissipate. Meanwhile my fleece leggings feel unbearably clammy after a mild walk. However if you’re not moving, wool will leak body heat faster than fleece at the same weight
Cashmere is considered the cadillac of wools because it is the softest wool available en masse, but also because it traps more heat per unit weight than other wool. If a nice heavy sweater is a feature for you, consider superfine merino wool, which is cheaper, almost as soft, and has some chance of being machine washable. While I can’t prove this I suspect you’re also less likely to be ripped off by fake or low quality merino, since if you’re going to lie it might as well be a more expensive wool.
Other tips
You can 80/20 ironing by hanging the item on a hanger in the bathroom while you shower.
If you’re buying natural fibers and especially wool used, put it in the freezer for three weeks and run it through the dryer (while already dry, you’ll ruin the fabric if it’s wet) to kill moth eggs.
If you’re not a coward, “hand wash only” can mean “inside out in a lingerie bag on delicate”. However the bit about using special detergent for animal-based fabrics is real: Regular detergent has enzymes that break down wool and silk.
Cable knit is very warm as long as there is absolutely zero wind. If you want to go outside you need a windproof layer on top of it.
Wind/waterproof clothing is very expensive, in part because it’s difficult to sew.
Fur is like diamonds and pianos in that the resale value is a small fraction of the retail cost. Used fur coats sell for less than new high quality winter coats, and sometimes less than used. However fur requires oil changes every few years or it will ?explode?, which brings the cost of ownership up. Fur is heavier than down or fleece per unit warmth. It does not handle moisture or crushing well.
It took me a long time to realize that Bell Labs was cool. You see, my dad worked at Bell Labs, and he has not done a single cool thing in his life except create me and bring a telescope to my third grade class. Nothing he was involved with could ever be cool, especially after the standard set by his grandfather who is allegedly on a patent for the television.
It turns out I was partially right. The Bell Labs everyone talks about is the research division at Murray Hill. They’re the ones that invented transistors and solar cells. My dad was in the applied division at Holmdel, where he did things like design slide rulers so salesmen could estimate costs.
[Fun fact: the old Holmdel site was used for the office scenes in Severance]
But as I’ve gotten older I’ve gained an appreciation for the mundane, grinding work that supports moonshots, and Holmdel is the perfect example of doing so at scale. So I sat down with my dad to learn about what he did for Bell Labs and how the applied division operated.
I expect the most interesting bit of this for other people is Bell Labs’ One Year On Campus program, in which they paid new-grad employees to earn a master’s degree on the topic of Bell’s choosing. I would have loved to do a full post on OYOC, but it’s barely mentioned online and my only sources are 3 participants with the same degree. If you were a manager who administered OYOC or at least used it for a degree in something besides Operations Research, I’d love to talk to you (elizabeth@northseaanalytics.com).
And now, the interview
Elizabeth: How did you get started at Bell Labs?
Craig: In 1970 I was about to graduate from Brown with a ScB in Applied Math. I had planned to go straight to graduate school, and been accepted, but I thought I might as well interview with Bell Labs when they came to campus. That was when I first heard of the One Year On Campus program, where Bell Labs would send you to school on roughly 60% salary and pay for your tuition and books, to get a Masters degree. Essentially, you got a generous fellowship and didn’t have to work as a teaching or research assistant, so it was a great deal. I got to go to Cornell where I already wanted to go, in the major I wanted, operations research.
Over 130 people signed up for the One Year On Campus program in 1970. That was considerably more than Bell Labs had planned on; there was a mild recession and so more people accepted than they had planned. They didn’t retract any job offers, but the next year’s One Year On Campus class was much smaller, so I was lucky.
The last stage in applying was taking a physical at the local phone operating company. Besides the usual checks, you had to look into a device that had two lighted eyepieces. I looked in and recognized that I was seeing a cage in my left eye and a lion in my right eye. But I also figured out this was a binocular vision test and I was supposed to combine the two images and see the lion in the cage, so that’s what I said I saw. It’s unclear if Bell Labs cared about this, or this was the standard phone company test for someone who might be driving a phone truck and needed to judge distances. Next time I went to an eye doctor, I asked about this; after some tests, he said I had functional but non-standard depth perception.
What did you do for Bell Labs?
I worked in the Private Branch Exchange area. Large and medium size companies would have small telephone exchanges that sat in their buildings. It would be cheaper for them because most of the calls would be within the building rather than to the outside world, and thus avoid sending the call to a regular exchange a number of miles away and then back to the building. You could also have special services, like direct lines to other company locations that you could rent and were cheaper than long distance charges. The companies supplied their own phone operators and the operating companies were responsible for training, and the equipment and its maintenance and upgrades.
Most calls went through automatically e.g. if you knew the number. But some would need an operator. Naturally, the companies didn’t want to hire more operators than they needed to. The operating company would do load measurements and, if the number of calls that needed an operator followed a Poisson distribution (so the inter-arrival times were exponential).
The length of time an operator took to service the call followed an exponential distribution. In theory, one could use queuing theory to get an analytical answer to how many operators you needed to provide to get reasonable service. However, there was some feeling that real phone traffic had rare but lengthy tasks (the company’s president wanted the operator to call around a number of shops to find his wife so he could make plans for dinner (this is 1970)) that would be added on top of the regular Poisson/exponential traffic and these special calls might significantly degrade overall operator service.
I turned this into my Master’s thesis. Using a simulation package called GPSS (General Purpose Simulation System, which I was pleasantly surprised to find still exists) I ran simulations for a number of phone lines and added different numbers of rare phone calls that called for considerable amounts of operator time. What we found was that occasional high-demand tasks did not disrupt the system and did not need to be planned for.
Some projects I worked on:
A slide rule for salesmen to estimate prices on site, instead of making clients wait until the salesman could talk to engineering.
Inventory control for parts for PBX.
I worked with a Ph. D. mathematician on a complicated call processing problem. I ran a computer simulation and he expanded the standard queuing theory models to cover some of the complexities of reality. We compared results and they were reasonably similar.
Say more about inventory control?
The newest models of PBX’s had circuit packs (an early version of circuit boards), so that if a unit failed, the technician could run diagnostics and just replace the defective circuit pack. The problem was technicians didn’t want to get caught without a needed circuit pack, so each created their own off-the-books safety stocks of circuit packs. The operating company hated this because the circuit packs were expensive, driving up inventory costs, and further, because circuit packs were being constantly updated, many off-the-book circuit packs were thrown out without ever having been used. One operating company proceeded with inspections, which one technician countered by moving his personal stock to his home garage.
This was a classical inventory control problem, a subcategory of queuing theory. I collected data on usage of circuit packs and time to restock, and came up with stocking levels and reorder points. Happily, the usual assumptions worked out well. After a while, the technicians were convinced they were unlikely to get caught short, the company was happy that they had to buy fewer circuit packs and they were accessible to all the technicians. Everyone was happier.
And the slide rule?
While I was in graduate school, I became interested in piecewise linear regression (aka segmented regression), where at one or more points the regression line changes slope, jumps (changing its intercept) or both.
I considered working on PLR for my Ph.D. dissertation. On my summer job back, I saw a great fit with a project. Salespeople would go out to prospective PBX customers but be unable to give them a quick and dirty cost estimate for a given number of phone lines, traffic load, etc. It was complicated, because there were discontinuities: for example, you could cover n phones with one control unit, so costs would go up linearly with each additional phone. But if you had n +1, you had to have two control units and there would be a noticeable jump in costs. There were a number of wrinkles like this. So the salesperson would have to go back to the office, have someone make detailed calculations and go back out to the customer, which would probably lead to more iterations once they saw the cost.
But this could be handled by piecewise regression. The difficult problem in piecewise regression is figuring out where the regression line changes, but I knew where they were: for the above example, the jump point was at n+1. I did a number of piecewise regressions that captured the important costs and put it on a ….
I bet you thought I was going to say a programmable calculator. Nope, this was 1975, and the first HP had only come out the year before. I had never seen one and wouldn’t own one for two more years. I’m not sure I could have gotten the formulae in the hundred line limit anyway. The idea of buying one for each salesperson and teaching them how to use them never came up. I designed a cardboard slide rule for them.
I found piecewise regression useful in my work. But that summer I recognized that research in the area had sputtered out after a couple of years, so I picked another topic for my dissertation.
Elizabeth: What did you do after your masters degree?
Craig: I worked at Bell Labs for a year, and then started my PhD in statistics at UWMadison. There were no statistics classes worth taking over the summer, so I spent all four summers working at Bell Labs.
How was Bell Labs organized, at a high level?
I interviewed for a job at Murray Hill, where the research oriented Bell Labs work was done. The job involved anti-ballistic missile defense and no secret details were gone into. I didn’t get that job. I worked in a more applied location at Holmdel.
I did go to one statistical conference at Murray Hill. The head of the statistical area there was John Tukey, a very prominent statistician. He simultaneously worked at Bell Labs and was head of the Princeton Statistics Department. You don’t see much of that any more.
There was a separate building in the area that did research in radio telescopes. This was an outgrowth of research that investigated some odd radio interference with communication, that turned out to be astronomical. I was never in that building.
However, Bell Labs didn’t skimp on the facilities at Holmdel. It had an excellent library with everything I needed in the way of statistics and applied math. The computer facilities were also first-rate, comparable to that at the University of Wisconsin where I got my PhD.
Holmdel worked with the operating phone companies who provided actual phone service in their own geographical areas. People at Holmdel would sometimes take exchange jobs at operating companies to better understand their problems. One of these came back from a stint in New York City and gave a talk where he showed a slide of people pushing a refrigerator out of an upper story window of a derelict building while a New York Tel crew was working underneath them.
A more common problem was that by the time I was there, technicians were not as bright as they had been. A bright person who could not afford to go to college or maybe even finish high school in 1940 and had become a technician in an operating phone company had kids who could go to college, become engineers and be about to start work at Bell Labs in 1970.
How was management structured?
My recollection was that a first line-manager had a mean of 8 or 9 people. This varied over time as projects waxed and waned. I have a feeling that new first-line managers had fewer people but I don’t ever recall hearing that officially.
There was a different attitude about people (or maybe it was a different time). My boss at Bell Labs had told them he was resigning to work at another company. An executive vice president came to visit him, said he had a bright future at Bell Labs and suggested he’d wait a while. He decided to and was soon promoted.
Feedback was mostly given by yearly performance appraisals, as it was at all the companies I worked for. Occasionally you’d get informal feedback, usually when some client was unhappy.
Bell Labs was big on degrees. To be a Member of Technical Staff you had to have electrical engineering classes and a Masters degree or on a path to get one. They were willing to pay for this.
What were the hours like?
For me it was a regular 9 to 5 job. I assume managers worked longer and more irregular hours but no one ever asked me to work late (I would have done if they’d asked). The only time I can remember not showing up at 9 was when I got in really late from a business trip the night before.
There was a story I heard while I was at Bell Labs which I have no idea is true. Walter Shewhart worked at Bell Labs. In 1956, he was 65, and under the law at the time, had to retire. The story goes that they let him keep an office, in case he wanted to stop by. Instead, he kept showing up at 9 and working until 5 every weekday. Eventually, they took the office away from him.
Who decided what you worked on? What was the process for that?
To be honest, I didn’t think much about that. I got my jobs from my first line manager. I kept the same one for my entire time at Bell Labs; I don’t think that was common. You may have noticed that I did a lot of work in the queuing and inventory area; my Master’s thesis was in that area and I’m guessing that my boss saw I was good at it and steered those kind of jobs to me. With my last task, getting a rough pricing approximation for PBX’s, I was handed the job, saw that piecewise regression was a great solution, talked to my boss about it and he let me do it that way. I don’t know how jobs got steered to him.
What was the distributions of backgrounds at Bell Labs?
I went with to Cornell for One-Year-On-Campus. Of the 5 people in my cohort: I was from Brown, one from Cornell, one from University of Connecticut and one from Indiana. So I’d say they were from at least good schools, so that the Labs would be sure they would be able to compete at Cornell.
Not everybody at the Labs came from elite schools. As the most junior member of the unit, who knew less about phones then anybody else, I didn’t enquire about their resumes. I was berated by one of members of my group for using meters for a wavelength in a meeting instead of “American units”. He had a second part-time job as a stock-car racer, but while I was there he decided to quit after his car was broken in half in a crash. Another man in my group had a part-time job as a photographer. When I came back from Cornell for my Christmas check-in at Bell Labs, he was dead in a train “accident”. Local consensus was that he had been working on a divorce case and got pushed in front of a train
My impression was that Bell Labs didn’t poach much from other technical companies. They wanted to hire people out of school and model them their own way.
Since the One-Year-On-Campus people were sharp and had Master’s, a lot of them got poached by other companies. Of the five people I kept track of, all five had left the Labs within five or six years.
As to age distribution, there were a considerable number of young people, from which there was considerable shrinkage year to year. After five to 10 years, people had settled in and there was less attrition. They were good jobs. Although not as numerous (I think because the Labs had expanded), there were a number of people who had been there for decades.
How independent was your work?
I did work with that Ph. D. mathematician on a queuing problem.
I can’t believe that they let me work on my own project in the two months between when I arrived at Holmdel before I left for Cornell. But I don’t remember what it was.
In retrospect, I am surprised that the Labs let me interview possible hires by 1972 when I’d only been around for a year (not counting the year at school). Admittedly, I was supposed to assess their technical competence. I think I did a good job; I recommended not hiring someone who they hired anyway. I later worked with her and my judgement was correct. She was gone within a year.
Tell me more about One Year on Campus
Bell Labs would pay tuition and expenses for a master’s degree along with 60% of your salary, as long as you graduated in the first year. There also was an option to stay on full salary and go to grad school part time, but I didn’t do that. You could theoretically do this for a PhD but it was much harder to get into; I only knew one person in my division who did so.
One qualification was that you had to have a year of electrical engineering (or spend a year at the Labs before going). Fortunately, although my degree was in Applied Math, I had taken some electrical engineering as an elective. Partially out of interest, and partially because my grandfather had worked his way up to being an electrical engineer [note from Elizabeth: this was the grandfather on the television patent].
An important caveat was that you need to get your degree completed in a year or you would be fired. I never heard of this actually happening, but I was motivated.
Bell Labs would also pay for you to take classes part-time and give you a half-day off; I went to the stat department at Columbia and took my first design of experiments class there and fell in love.
What was so loveable about experimental design?
My love affair with design of experiments started in my first class on the subject. The professor told a story of attending at a conference luncheon at Berkley and was seated between two Nobel laureates in physics. One of them politely asked him what he did and the professor gave him this weighting design example.
You have a balance beam scale, where you put what you want to weight on one side and put weights on the other side until it balances. You’re in charge of adding two chemicals C1 and C2 to a mixture. They come in packages with nominal weights, but the supplier is sloppy and the precise ratio of them is important to the quality of the mixture. However, this is a production line and you only time to make two measurements per mixture. What two measurements do you do?
The obvious answer is you weigh C1 and then you weigh C2.
But this is wrong. A better solution is to put C1 and C2 in the same pan and get their combined weight WC. Then you put C1 in one pan and C2 in the other, and you get the difference between them, WD. Then if you add WC + WD, the weight of C2 cancels out and you get an estimate of 2*C1. If you subtract WD from WC, the weight of C1 cancels out and you get an estimate of 2*C2. Notice that you’ve used both weighings to determine both weights. If you run through the math, you get the same precision as if you weighed both chemicals twice separately, which is twice the work.
The physicist got excited. The other Nobel laureate asked what they were talking about, and when he was told, said: “Why would anyone want to measure something more precisely?”. That is the common reaction to the design of experiments.
But even more important than efficiency, designed experiments can inform about causality, which is very difficult to determine from collected observed data. Suppose there is impurity that varies in a feedstock that is fed into a chemical reactor that lowers the quality of the output but we don’t know this. The impurities also cause bubbles, which annoy the operator, so he/she increases the pressure to make them go away. If we look at a plot of quality vs. pressure, it will look like quality decreases as pressure increases (when actually it has nothing to do with it; correlation does not imply causality). But if we run a designed experiment, where we tell the operator which runs are supposed to be run at high pressure and which are to be run at low pressure, we have a good shot of figuring out that pressure has nothing to with quality (the greater the number of experiments, the better the odds). If we then talk with the operator and they explain why they increase pressure in production, we have a lead on what the real problem might be.
What if you don’t care about efficiency or causality? The following example is borrowed from Box, Hunter and Hunter “Statistics for Experimenters”, first edition, pp. 424ff. A large chemical company in Great Britain makes fertilizer. Because the cost of fertilizer is low, transportation costs are a noticeable part of it, so when demand goes up, instead of adding onto a current plant, they build a standard plant at a blank spot on the map. Unfortunately, this new plant’s filtration times nearly doubles, meaning this multi-million pound plant (currency, not weight) is operating at half capacity. Management goes nuts. There is a very contentious meeting that comes up with 7 possible causes. Box comes up with a first round plan to run 8 experiments. This is the absolute minimum, since we need to estimate the mean and the seven effects. This is important, because we’re not doing experiments in a flask, but in a factory. Changing one factor involves putting a recycle device in and out of line, etc., so it won’t be quick.
What do you do? The usual reaction is to do a one-at-a-time experiment, where we have a base level (the settings of the last plant previously built) and then change one factor at a time. This is generally a bad idea and, as we shall see, this is a particularly bad idea in this case. First, as a multiple version of the weighing design, we only use two points out of the eight to determine the importance of that factor. And suppose we botch the base level?
Instead, Box did a fractional factorial design, with eight design points such that we code a factor levels as 1 if it’s at the factor level of the working correctly plant and -1 at the new plant’s settings.
Then if we add the four settings of, say factor 1, that are 1 and subtract the four that are -1, we estimate 8 times the distance between the new pant and the neutral 0 settings and and all other factors are at their neutral setting. Similarly for all the factors. Box used the fractional factorial design that included all old plant settings. Its filter time was close to the old plant’s, which reassures us we have captured the important factors. If we do the same for all factors, the magnitudes of factors 1, 3, and 5 are considerably larger than the other four. However, chemistry is interaction and each of the large magnitude factors is confound with the two-factor of the other two large magnitude factors. Fortunately, we can run an additional eight runs to estimate triplets of two factor interactions, because we didn’t blow our whole budget doing one-at-at-time experiments. It turns on that the triplet that includes factor 1*factor 5 interaction has a large magnitude interaction, which could reasonably explain why the original factor 3 estimation magnitude appeared to be large. However, management wanted to be sure and ran a 17th experiment with factor 1 (water) and factor 5 (rate of addition of caustic soda) at the old plant settings and the other 5 were left at the new settings. The filtering time returned to the desirable level. Notice if we had done a one-at-time experiment we would never have been able to detect the important water*(rate of addition of caustic soda). There is a feeling that a lot of tail-chasing in industrial improvement is due to interactions not being recognized.
Another element of experimental design is blocking, where we suspect there are factors that we care about, like four different types of fertilizer and others don’t care about (say hill top land, mid-hill land and bottom land) but may effect the yield. The solution is to block so that each of the four fertilizers gets an equal share of the three land types. This eliminates the noise due to land type
Finally, within the limits of blocking, we wish to randomly assign treatments to factor settings. This provides protection against factors that we don’t realize make a difference. There was a large stage 2 cancer vaccine study which showed that the treatment group lived 13 months longer than the control group. The only problem was that who got the treatment was not decided at random but by doctors. It went on to a much more expensive stage 3 trial, which found no statistically significant difference between the vaccine and the control groups. What happened? It is surmised that since doctors can make a good guess at your prognosis and desperately want to have another tool to fight cancer, that they unconsciously steered the less sick patients to the vaccine group.
Thanks to my Patreon Patrons for supporting this post, and R. Craig Van Nostrand for his insider knowledge
On some level, calories in calories out has to be true. But these variables are not independent. Bodies respond to exercise by getting hungry and to calorie deficit by getting tired. Even absent that, bodies know how much food they want, and if you don’t give it to them they will tell you at increasing volume until you give in (not all bodies, of course, but quiet stomachs aren’t the target market for GLP-1s). A new breed of drugs, GLP-1 agonists, offer a way out of the latter trap by telling your body you’ve eaten, even when you haven’t, but leave many people fatigued. The newest GLP-1, retatrutide, may escape that trap too, with a mechanism so beautiful I almost don’t believe it.
How Jelly Beans Become Fat
Unfortunately in order to understand the beauty of retatrutide, you’re going to have to learn the basics of energy metabolism in the body. I’m sorry.
You have probably heard of mitochondria, the power house of the cell. What that means is mitochondria takes in sugar, protein, or (components of) fat and turns them into ATP, which is then used to power chemical reactions in your cells. This is the equivalent of a power plant that uses nuclear, coal, and hydro to power small batteries and mail them to your house.
Sugar is a desirable fuel because it can produce ATP very quickly, and if push comes to shove, can do so without oxygen. Your body works to maintain a particular concentration of sugar in your bloodstream, so your cells can take in more when they need it. This is especially important for your brain, which runs mostly on sugar.
Fat is your body’s long-term energy storage. If you eat fat and don’t immediately burn it, it will be directly added to adipose (fat) cells. Dietary sugar you don’t use will be converted into fat and stored in the same cells. This is beneficial because fat is very space-efficient, but the process of converting sugar to fat is calorie-inefficient: you lose 10-25% of the energy in sugar in the conversion to fat (this means that how many calories you get from a jelly bean will depend on whether you burn the sugar immediately or store it as fat and burn it later)
Under the right circumstances (weasel worded because I’ve yet to find a satisfactory explanation of when this happens), fat will break down into fatty acids, which circulate like sugar until a cell draws them in to create ATP. Breakdown of fatty acids can also produce ketone bodies, which are what powers your brain during fasts. Breaking down fat to produce ATP takes minutes.
So sugar works fast, but takes up a lot of storage space, is prone to undesirable reactions with nearby proteins, and is osmotically unstable*. Fat is space efficient and non-reactive but breaks down slowly, and frequent conversion is costly. Glycogen is somewhere in the middle- it’s a store of energy that breaks down into sugar faster than fat can produce fatty acids, but is more stable than raw sugar. If you’ve ever eaten a carb heavy meal and seen the scale go up way more than could be accounted for by calorie count, that’s the glycogen. Each gram of sugar is stored with 3-4 grams of water, so it can cause major swings in weight without touching fat cells.
There are glycogen stores in your muscles for their personal use during intense activity. There’s also a large chunk in your liver, which is used to regulate blood sugar across your entire body. If your blood sugar is low, your liver will break down glycogen into glucose and release it into the blood, where whatever organ that needs it can grab it. If you’re familiar with “the wall” in endurance exercise: that’s your body running out of glycogen. Your second wind is fat being released in sufficient quantities. In general your body would rather use glycogen than fat, because glycogen loses almost no energy in the conversion from and to sugar and fat loses a lot.
The Power Plant Managers
Managing these stores of energy is a complicated web of hormones.
When your blood sugar is high, the hormone insulinis released totrigger certain cells, including muscle and fat cells, to take said sugar from the blood and use it. Type 1 diabetics don’t produce enough insulin. Type 2 diabetics produce insulin but their cells respond to it more weakly (known as insulin resistance).
When your blood sugar is low, the hormone glucagon triggers your liver to break down glycogen to release sugar, raising your blood sugar, suppressing insulin, and giving you more energy. It more weakly triggers the breakdown of fat. release. Glucagon also triggers the release of the hormone cortisol.
Cortisolgets a bad name as the stress hormone, but the only thing worse than stress with high cortisol is stress with low cortisol. If you stumble along a tiger in the jungle, you want cortisol. It also increases blood sugar and energy levels (to provide energy to escape the tiger). Energy for running sounds good for weight loss but empirically cortisol promotes fat storage and muscle breakdown, and increases insulin resistance. This may be why raising glucagon alone does not cause weight loss.
Glucagon-like peptide 1, or GLP-1 is one of the hormones that tells your brain “I’m eating food”. It is triggered by the presence of calories in the gut, bile in the stomach, or even the knowledge that you’re about to eat. It suppresses appetite and glucagon (preventing the breakdown of glycogen), increases insulin (and thus sugar uptake into cells), and slows down the movement of food through your intestines.
The hormone glucose-dependent insulinotropic polypeptide (abbreviated GIP for historical reasons) is also triggered by calories in the gut. It encourages insulin sensitivity (meaning a given molecule of insulin will cause a cell to uptake more sugar) and fat storage.
I used the phrase “hormone X does Y” a lot, but it’s kind of misleading. Hormones are more or less arbitrary molecules, their shape doesn’t mean anything, just like the word “toast” doesn’t inherently mean “bread exposed to high, dry heat” or “raise a glass to”. Hormones’ meaning comes from the receptors they activate. Hormone receptors are molecules that straddle the membranes of cells.
The “outside” end of a receptor waits to be activated by a hormone molecule. When it does, the “inside” end of the receptor does… something. That something can depend on the activating molecule, the cell type, conditions inside the cell, phase of the moon…
….whereas hormones and receptors are blobs. Some blobs don’t fit together at all, some fit as well as a key in a lock (strong affinity), and some fit together like puzzle pieces that don’t quite interlock, but are close enough (weak affinity). Receptors are much less specific than locks, and don’t have a 1:1 relationship with hormones even when they are named after one. E.g. GLP-1 Receptor (GLP1R) has strong affinity for GLP1 but also weak affinity for glucagon, because their blob shapes are close enough to each other.
[glucagon (red) and glucagon receptor (blue)] [adapted from]
I bring this up because some drugs referred to as GLP-1s hit more than one receptor, and this is important for understanding GLP-1s.
How do GLP-1 Medications Work?
So GLP-1 the peptide hormone works by activating receptors that tell your brain you’ve eaten and don’t need more food. How do GLP-1s, the class of medication, work?
Semaglutide (aka Ozempic and Wegovy) activates only GLP1Receptor. We’ve covered why that helps, but often comes at the cost of fatigue.
Tirzepatide (Zepbound) activates GLP1R and GIPR, and no one is sure why the latter helps but it seems to.
Retatrutide (no retail name) activates GLP1R, GIPR, and glucagon receptor. The glucagon receptors encourage the breakdown of glycogen and fat, which your body will use as energy. You might hope this would cause weight loss on its own, but in practice it doesn’t. Even if it did, permanently elevated glucagon would raise blood sugar to undesirable levels for undesirable periods of time. But GLP-1 is great at managing blood sugar. If only there was a way to keep it from making you tired…
So glucagon’s and GLP-1’s positive effects (burn more energy/eat less food) are synergistic, but their negative effects (elevated blood sugar/fatigue) cancel out. It’s elegant at a level rarely seen in biochemistry.
Just taking these hormones won’t help much, because all three have a half-life of less than 10 minutes. You’d need to be on a 24/7 IV infusion for them to maintain levels long enough to be useful.
This is where big pharma pulls its weight. All three medications feature minor edits to the chemical structure of the hormone that don’t affect its work as a key but do slow your body’s ability to digest it (which they can get away with because key fit is fuzzy, not precise). Tirzepatide and retatrutide are further modified to fit the extra receptor(s) they target. This is easier because all three of GLP-1, glucagon, and GIP are peptide hormones, meaning they’re made up of amino acids, and it’s easy to substitute one amino acid for another (well, easy compared to modifying other kinds of hormones).
Then chemists attach that altered peptide hormone molecule to a chain of fatty acids. The acids are slowly picked off over days: when the last one is removed the remaining molecule briefly fits into its locks/receptors, before being digested (but not as quickly as if it were the unmodified hormone). Because this removal happens at a slow, predictable pace, it spaces out the availability of the molecule, getting you the same effect as an IV drip with a lower dosage each day. And thus fat is the instrument of its own undoing.
The Side Effects
Reminder that I am some lady who reads stuff on the internet and writes it down and the fact that I couldn’t find a better version of this should make everyone involved feel bad. That said.
The common side effects of all three GLP-1s are digestive distress and injection site reactions. The former makes sense- GLP-1s screw with your digestion, so you’d expect the side effects to show up there. The latter might be a combination of the volume and pH level of the injection.
Fatigue is another common side effect (it’s reported at only 7%, compared to 3% for placebo, but anecdotally seems worse). It’s unclear if this stems directly from the medication or the body’s normal protective reaction to a calorie deficit. There’s no data yet, but retatrutide’s 3rd mechanism of action (imitating glucagon) may counteract fatigue or even give people more energy (trip report from one such lucky person).
There’s no data on this either, but if GLP-1s cause fatigue due to calorie deficit, I wonder what they do to the immune system, which is among the first of your systems to suffer from energetic budget cuts.
People who lose weight often lose muscle as well as fat. This might happen at slightly higher rates for people losing weight through GLP-1s, or they might just be selected for not exercising much. Weight lifting and protein consumption help (note that this may require planning to fit into your new, lower calorie budget).
In rodent studies, semaglutide and tirzepatide were both found to increase the rate of thyroid tumors. There’s no data on retatrutide yet but no reason to expect it to be different. It’s even less clear than usual if this rat finding will transfer to humans, because the rodents have several factors making them much more susceptible to thyroid cancer. If you have a family history of thyroid cancer or something called MEN2, GLP-1s probably aren’t for you.
Another concern is drug interactions. GLP-1s will obviously interact with other drugs that affect blood sugar, so be cautious around that. So far as we know they don’t affect the production of liver enzymes that digest medications, which precludes a major source of drug interactions. However they will lead medication to sit in your gut longer, which might increase their effective dose. And any drug that’s highly sensitive to body weight, like warfarin or lithium, will need monitoring as you lose weight.
Conclusion
I don’t like the idea of everyone being on a compound to mitigate a problem that modernity caused, forever, any more than anyone else does. But I’m unexpectedly impressed with the elegance of this solution (in a way I’m not for antidepressants, which have great empirical results but give us only the vaguest idea of how they work). It’s not clear this should make me feel better, but it does.
*Osmotically unstable means that there’s a semi-permiable barrier and for some reason water will cross the barrier more in one direction that the other. In this case, the inside and outside of the cell “want” to have the same percentage sugar, but if a cell is stuffed full of sugar that will attract too much water and the cell will burst. If the cell has less sugar than the environment, it will leak and potentially dehydrate to death; this is one reason bacteria struggle to live on honey.
It’s amazing how much smarter everyone else gets when I take antidepressants.
It makes sense that the drugs work on other people, because there’s nothing in me to fix. I am a perfect and wise arbiter of not only my own behavior but everyone else’s, which is a heavy burden because some of ya’ll are terrible at life. You date the wrong people. You take several seconds longer than necessary to order at the bagel place. And you continue to have terrible opinions even after I explain the right one to you. But only when I’m depressed. When I’m not, everyone gets better at merging from two lanes to one.
This effect is not limited by the laws of causality or time. Before I restarted Wellbutrin, my partner showed me this song.
My immediate reaction was, “This is fine, but what if it were sung in the style of Johnny Cash singing Hurt?” My partner recorded that version on GarageBand for my birthday, and I loved it, which means I was capable of enjoying things and thus not suffering from distorted cognition, just in case you were wondering. But I restarted Wellbutrin just to see what would happen, and suddenly the original recording had become the kind of song you can’t describe because you sound too sappy, so all you can say is it brings you to tears. My partner couldn’t tell the difference, so my theory is that because I was the one who took the drug to make the song better, only I remember the old, mediocre version.
The effect extends to physical objects. As previously mentioned, I spent the first half of 2024 laid up with mold poisoning. For about half of that time, I knew the problem was under the bed* (I’d recently bought a storage bed that was completely surrounded with drawers). In that time I bought dozens of air filters, spent $4k on getting my entire house scrubbed and set up a ventilation system under my bed. I did everything except replace the mattress. This was due to the mattress being too heavy for any human being to lift and everyone was too busy to help me.
And even if I had found mold in the mattress, what could I have done about it? The websites for mattresses and bed frames are labyrinths that require feats of strength and skill to defeat. Nor was it possible to get the mattress out of my apartment, so it would just continue leaking the spores in a slightly different place.
Then I restarted a second antidepressant (Abilify, 2mg). The mattress was still too heavy for me, but suddenly light enough that it wasn’t an unspeakable imposition to ask my partner to flip it against the wall. And at the exact same time, the manufacturer’s website simplified itself so I could not only order a copy of my current mattress, but ask for a discount because my old one was so new (it worked! They give half off if you waive return rights). Less than a week after I started Abilify I was sleeping on a new mattress on a new frame, the old mattress and frame were at the dump, and my mold symptoms began to ease.
Given how well they work, taking antidepressants seems downright prosocial, so why are some people reluctant to try them? Sometimes they’re concerned that antidepressants work too well and turn everyone into a happy zombie. This is based on the fallacy that antidepressants work on you rather than on your environment. The fact that everyone is suddenly better at lane merges doesn’t make me incapable of being sad about medical setbacks. If having your world-is-easy meter set two steps higher seems like a bad thing, consider that that may itself be a symptom of your world-is-easy meter being set too low.
Pills aren’t the only way to make the outside world bend to your will, of course. Diet and exercise have a great reputation in this arena, matched only by the complete lack of effect of wishing for good diet and exercise. Luckily, one of the ways antidepressants change the environment is making weights lighter, lung capacity higher, and food take fewer steps to prepare. So if you’ve spent a few years knowing you should improve your diet and exercise routine without managing to get over the hump to actually doing it, maybe it’s time to give the everything-is-easier pill a try. Especially because the benefits extend not only to you, but to everyone on the highway with you.
Caveats
I’ve had an unusually good experience with antidepressants and psychiatrists. The first two antidepressants I tried worked very well for me (the second one is only for when things get really bad). I didn’t have to cycle through psychiatrists much either.
The most popular antidepressants are SSRIs, which I’ve never taken. My understanding is they are less likely (and slower) to work and have a worse side-effect profile than Wellbutrin, whose dominant side effects are weight loss and increased libido (but also insomnia and a slight increase in seizure risk). I’ve heard of good reasons not to start with Wellbutrin, like a family history of seizures or being underweight, but (I AM AN INTERNET WEIRDO NOT A DOCTOR) they seem underutilized to me.
Acknowledgements
Thanks to Patrick LaVictoire and the Roots of Progress Blog Building Fellowship for comments and suggestions. Thanks to CoFoundation and my Patreon patrons for financial support.
*Medicine being what it is I’m still only 95% that this was the cause, and was less certain yet before I got the mattress off the frame and examined it
From 2019 to 2022, the cryptocurrency exchange FTX stole 8-10 billion dollars from customers. In summer 2022, FTX’s charitable arm gave me two grants totaling $33,000. By the time the theft was revealed in November 2022, I’d spent all but 20% of it.
The remaining money isn’t mine, and I don’t want it. I would like to give this money to the FTX estate, but they are not returning my calls. If this post fails to get their attention in the next month, I will donate the money to Feeding America. In the meantime, I’d like to talk about why I made this decision, and why I think other people should do likewise.
Background
FTX was a crypto-and-derivatives exchange that billed itself as “the above board, by the book legitimate, exchange.” Several of its executives were members of Effective Altruism, a movement based on ruthlessly prioritizing donations to do the greatest good for the greatest number. EA’s presence in FTX was strong enough that FTX booked an ad campaign around CEO Sam Bankman-Fried’s intent to spend his wealth on good causes.
He is now serving a 25 year prison sentence for fraud.
Starting in 2021, FTX began to firehose money. $93m to political causes (some of which was probably buying favorable regulation) and $190m to explicitly philanthropic ones. The donations include domains like AI safety (e.g. $5m for Ought, which aims to make humans wiser using AI), biosecurity ($10m for HelixNano, which develops vaccine and other anti-infection tech), and Effective Altruism (e.g. $15m for Longview Philanthropy, itself a fundraising org). Donations also probably went to animal welfare organizations and global development, but these were made by a different branch of the FTX Foundation and there’s no clear documentation.
Some of that philanthropic money was distributed through a regrantor program that authorized agents to make grants on their own initiative, with some but not much oversight from FTX. It funded things like the memoirs of someone who worked on Operation Warp Speed, many independent AI safety researchers, and in my case, a project to find or train new research analysts who could do work similar to mine, or assistants to help them.
After the bankruptcy, I waited to be contacted by the FTX estate asking for their money back. Under US bankruptcy law I was outside the 90-day lookback period in which clawbacks are easy, but within the two-year period where they were possible. I did receive one email claiming to be from the estate, but it had a couple of oddities suggesting “scam” so I ignored it, and never received any follow-up. In November 2024, the statute of limitations for clawbacks passed, and with it, any legal claim anyone else had on the money.
For the next few months, I did nothing. Everyone I knew was keeping their money and seemed very confident that this was fine. And all things being equal, I like money as much as the next person.
But I couldn’t stop picturing myself trying to justify the choice to keep the money to a stranger, and those imaginary conversations left me feeling gross. None of my reasons seemed very good. When I finally entertained the world where I returned the money voluntarily, I felt hypothetically proud. So I decided to give it back, or at least away.
“Avoid tummy aches” isn’t exactly a moral principle. Avoiding my tummy aches is especially not a principle I can ask others to follow. But in the course of arguing with my friends who didn’t think I should give away the money, and trying to figure out where I should donate, I eventually figured out the rules I was implicitly following, and what I would ask of other people.
Protecting the Golden Goose
The modern, high-trust, free-market economy is a goose laying golden eggs. It has moved the subsistence poverty rate from 100% to 47%, lowered urban infant mortality from 50% to less than 1% in developed countries. It brings a king’s ransom in embroidery floss directly to my house for a fraction of an hour’s wage.
This is $30, and I’m disgusted because it’s not pre-loaded onto bobbins.
The most important thing in the world after extinction-level threats is to keep this goose happy and productive, because if the goose stops laying, then we don’t have any gold to spend on things like vaccine cold chains or cellular data networks. Every theft gives a little bit of poison to the goose. A norm that you can steal if you have a good reason will kill the goose, and then we will be back to the nasty, brutish, and short lifespans of our agricultural ancestors. This is true even if your reason is really, really, really good.
Given how damaging theft is to the goose, it’s important to keep the incentives to steal as low as possible. One obvious way is to not let thieves keep the money. For most thieves this is enough, because having the money themselves was the whole point. But in this weird case where the theft was at least partially to fund philanthropic projects, it’s important to not spend the money on those projects.
That ship has mostly sailed, of course. Even if I gave back/away all the money FTX gave me, I still did a bunch of work they wanted. Giving the money away doesn’t erase the work, and would violate another principle in the care and feeding of golden geese, that people get to keep what they earned.
But I only spent 80% of the money (some on my own salary, some on researchers I was trialing). The other 20% wasn’t earned by me or anyone else. I could earn it now, with a new project- my old project had wrapped up but my regrantor had given permission to redirect to anything reasonable before the bankruptcy. I have a long backlog of projects; it wouldn’t be hard to just do one and conceptually bill it to FTX. But given that I had FTX’s (indirect) blessing on arbitrary projects that means doing any of them would reward the theft.
(If it seems crazy to you that FTX executives genuinely believed they stole for the greater good and all that altruism wasn’t just a PR stunt, keep in mind that they believed the world was at risk of total annihilation in 5-10 years due to artificial superintelligence. I also know some people who knew some people, and they’re really sure that at least some of the executives were sincere at least at the start.)
Having decided I can’t keep it, where should the money go? Obviously the best place would be the victims of FTX’s theft. The only way I know of to give to them is via the FTX estate. The estate has an email address for people who wish to voluntarily return money but I guess they’re not checking it, because I’ve been emailing them for months with no reply.
Some of you may argue that the FTX users are already going to be made whole, in fact 120% of whole, because FTX’s investments did well and the estate will be able to pay all the claims. This is technically true, but it uses the valuation of crypto assets at the time of bankruptcy. Since then bitcoin has 6xed; 20% doesn’t begin to cover the loss. It might not even cover inflation + compound interest.
My next choice was to donate to investigative journalism in crypto- if I couldn’t redress crypto theft, maybe I could prevent it. Unfortunately, there doesn’t seem to be anyone who’s good at this, still working, and will accept donations higher than $5/month. You might think, “Surely he would accept larger amounts if offered, even if he doesn’t list it on his website,” but no, my friend tried to give him money months ago, and he refused. And there was no second choice.
If I can’t give it to the victims or prevent future victims, my third choice was wherever it would do the most good, in an area FTX Foundation didn’t value (so as to not reward theft). This is hard because while FTX funded a lot of stupid things, they also covered a long list of good things. I, too, hate AI risk and deadly pandemics. After sampling a bunch of ideas, I eventually settled on Feeding America. Feeding hungry people may not have the highest possible impact, but it’s hard to argue that it’s not helping. FTX never hinted at caring much about American poverty. I don’t know anyone involved with Feeding America, so there’s no possibility of self-enrichment. And 10 years ago, I heard a great podcast on how they used free-market principles to make their food distribution vastly more efficient.
I don’t feel amazing about this choice. I don’t think amazing was an option once the FTX estate declined my offer. But I feel good enough about this, and there’s no good way to optimize when you’re specifically trying to thwart optimizers like the FTX executives. All I can do is make sure I’m living up to my principles and make some people a little less hungry.
The Widow’s Mite Isn’t Worth Very Much
Do I think other people are obligated to give away their FTX grants? The answer is closer to yes than no, but not without complications.
I think people should give back/away FTX money they hadn’t already spent or earned. But I take a liberal definition of spending and earning. If I hadn’t paid my taxes on those grants at the time of the bankruptcy, I’d still consider the taxes already spent, because accepting the money committed me to paying them (although FTX told me I didn’t need to pay taxes on the grant. This is the clearest sign I received that Something Was Wrong with the FTX Foundation, and to my shame, I ignored it as standard Effective Altruism messiness). I know someone who quit their job and moved countries on the assumption that the FTX money would always be there, and while I think that was a stupid decision even absent the fraud, the cost of moving back home and reestablishing her life counts as “already spent.” She might have to give back something, but accepting the grant and assuming its good faith shouldn’t come with a bill.
But it was not random happenstance that it was easy for me to drop my FTX-funded project on a dime when scary rumors started. I work as a freelancer, sometimes balancing many projects from many clients and sometimes having none but my own (which necessitates a healthy cushion of savings). So when the word came down that FTX was at risk and the responsible thing to do was to stop spending their grants, it was just another Tuesday for me to stop their project. To the extent that giving up this money is morally praiseworthy, I think the praise should accrue to the decisions that made giving up the money easy, rather than the actual donation.
This is not a popular belief. Most people’s view on charity is summed up by the biblical story of the widow’s mite, in which a poor widow giving up a small amount at great personal sacrifice is considered more virtuous than large donations from rich men. I can see the ways that’s appealing when trying to judge someone’s character. But even if we’re going to grade people on difficulty, we have to look further back than the last step. If the rich men worked hard and made sacrifices to achieve their wealth, and they chose to invest that money in helping others rather than yachts, that should be recognized (although of course this doesn’t justify hurting others to get that money; I’m talking only about personal sacrifice).
So I think people in my exact position have a strong obligation to give away leftover money from FTX. I think people in the related position of technically having unspent money but finding it too great a hardship to give back shouldn’t ruin their lives by doing so. But I encourage them to think about what they would need to change in their life to make ethical behavior easier.
Thanks
Thanks to the Progress Studies Blog Building Initiative and everyone who argued with me for feedback on this post.
Ketamine is an anesthetic with growing popularity as an antidepressant. As an antidepressant, it’s quite impressive. When it works, it’s often within hours- a huge improvement over giving a suicidal person a pill that might work 6 weeks from now. And it has a decent success rate in people who have been failed by several other antidepressants and are thus most in need of a new option.
The initial antidepressant protocols for ketamine called for a handful of uses over a few weeks. Scott Alexander judged this safe, and I’m going to take that as a given for this post. However, newprotocols are popping up for indefinite, daily use. Lots of medications are safe or worth it for eight uses, but harmful and dangerous when used chronically. Are these new continuous use protocols safe?
That’s a complicated question that will require several blog posts to cover. For this post, I focused on what academic studies of test tube neurons could tell us about cognitive damage, because I know which organ my readers care about the most.
Reasons to doubt my results
First off, my credentials are a BA in a different part of biology and a willingness to publish. In any sane world, I would not be a competitive source of analysis.
My conclusions are based on 6 papers studying neurons in test tubes, 1.5 of which disagreed with the others. In vitro studies have a number of limitations. At best, they test the effect on one type of cell, in a bed of the same type of cell. If any part of the effect of ketamine routes through other cells (e.g. it might hypothetically activate immune cells that damage the focal cell type), in vitro studies will miss that. It will also miss positive interactions- e.g., it looks like ketamine does stress cells out somewhat, in ways your body has protocols to handle. If this effect is dominant, in vitro would make ketamine look more harmful than it is in practice.
And of course, there’s no way to directly translate in vitro effects directly into real world effects. If ketamine costs you 0.5% of your brain cells, what would that do to you? What would 5% do? In vitro studies don’t tell us that.
All studies involved a single exposure of cells to ketamine (lasting up to 72 hours). If there are problems that come from repeated use rather than total consumption, in vitro can’t show it. However, I consider it far more likely that repeated exposures are much safer than receiving the same dose all at once.
Lastly, in vitro spares the ketamine from any processing done by the liver, which means you are testing only* ketamine and not its byproducts (with the exception of one paper, which also looked at hydronorketamine and found positive results).
[*Processing in neurons might not be literally zero, but is small enough to treat it as such for our purposes]
Tl;dr
I will describe each of the papers in detail, but let me give you the highlights.
Of 6 papers (start of paper names in parentheses):
2 found neutral to positive effects at doses higher than you will ever take
Highest dose with no ill effect:
2000uM for 24 hours (Ketamine incudes…)
500uM for 24 hours (but 100uM had positive effects) (Ketamine causes…)
2 found neutral to positive effects at dose you might achieve, but either didn’t test higher doses or found negative effects
1 uM for 72 hours (Ketamine increases…) but 0.5uM for 24 hours was better
1 uM for 24 h (nothing higher tested) ((2r,6r)…)
1 found no cellular mortality from ketamine on its own, but that it mitigated the effect of certain inflammatory molecules that would otherwise kill cells (ketamine prevents…)
1 found that ketamine killed cells at a dose you might take.
Lowest dose tested: 0.39uM for 24 hours (The effects of ketamine…). This is far less than where other papers found positive effects, and I’m not sure why.
This paper goes out of its way to associate ketamine with date rape in the first paragraph, which is both irrelevant and unfounded, so maybe the authors’ have a negative bias.
On the other hand, it calls cell mortality of up to 30% “relatively low toxic outcomes”, which sounds excessively positive.
For calibration: I previously estimated that a 100mg troche leads to a median peak concentration of less than 0.46uM, and a total dose of less than 2.8uM*h (to calculate total dose for each of the above papers, just multiply the concentration given by the time given. 1 uM for 24 hours = 24uM*h).
By positive effects, I mean one of two things: ketamine-exposed cells grew bigger and grew more connections with other cells; or, ketamine-exposed test tubes had more cells than their controls, which could mean cells multiplied, or that ketamine slowed cell death (one paper examined these separately, and the answer seemed to be “both.”). This appears to happen because ketamine stimulates multiple cell-growth triggers, such as upregulating BDNF and the mTOR pathway.
The primary negative effect is cell death, which stems from an increase in reactive oxidative species (you know how you’re supposed to eat blueberries because they contain antioxidants? ROS is the problem antioxidants solve). Unclear if there are other pathways to damage.
It doesn’t surprise me at all that two contradictory effects are in play at the same time. In fact, it wouldn’t surprise me if the positive effects were triggered by the negative- it’s not unusual in biology for small amounts of stress to trigger coping mechanisms that do more good than the stress did harm. For example, exercise also produces reactive oxidative species. Approximately everything real that helps with “detoxification” does so by annoying the liver into producing helpful enzymes.
The most actionable thing this post could do is give you the “safe” dose of ketamine”. Unfortunately, it’s hard to translate the research to a practical dose. There are several factors that might matter for the damage done by a drug:
The peak concentration (generally measured in µM = µmol/L, or ng/ml, which is uM*238)
The total exposure of cells to the drug, measured in concentration*time
How much your body is able to repair the damage from a drug. This will generally be higher when the total exposure is divvied up into many small exposures instead of one large one.
Alas, every study in existence uses a single large dose. But it probably doesn’t matter, because neurons in isolation are missing some antioxidative tools and the ability to replenish what they do have. So I’m left to guess how much safer divided doses are, relative to the single large dose used in every paper.
In an ideal world, the test tube neurons would be given ketamine in a way that mimics both the peak concentration and the total exposure. No one is even trying to make this happen. For most ways you’d receive ketamine for depression, you get an immediate burst followed by a slow decline. But for in vitro work, they dump a whole bunch of ketamine in the tube and let it sit there. Without the liver to break the ketamine down, the area under the curve is basically a rectangle. This makes it absolutely impossible for a test tube to replicate both the peak concentration and the total dose a human would be exposed to. The curves just look different.
[Statistical analysis by MS Paint]
In practice, and excluding the one negative paper, an antidepressant dose is rarely if ever going to reach the peak dose given to the test tube. You’re also not going to have anywhere near that long an exposure. My SUPER ASS PULLED, COMPLETELY UNCREDENTIALED, IN-VITRO ONLY, NOT MEDICAL ADVICE guess is that unless you are unlucky or weigh very little, a 100mg troche of ketamine will not do more oxidative damage than your body is able to repair in a few days (this excludes the risk of damage from byproducts).
There’s a separate concern about tolerance and acclimation, which none of these papers looked at, that I can’t speak to.
Papers
Warning: most of these papers used bad statistics and they should feel bad. Generally, when you have multiple treatment arms in a study that receive the same substance at different doses, you do a dose-response analysis- in essence, looking for a function that takes the dose as an input and outputs an effect. This lets you detect trends and see significance earlier.
What these papers did instead was treat each dose as if it were a separate substance and evaluate their effects relative to the control individually. This faces a higher burden to reach statistical significance.
Because of this, if there’s an obvious trend in results, and the difference from control is significant at higher levels, I report each individual result as if it’s statistically significant. I haven’t redone the math and don’t know for sure what the statistical significance of the effect is.
Interval between end of exposure and collection of final metric: 72 hours
As you can see in the bar chart, ketamine was either neutral or positive. However, less ketamine was more beneficial- there was more growth at the lowest dose of ketamine than the highest (which was indistinguishable from control), and more growth after a 24 hour exposure than a 72 hour exposure.
To achieve the same peak dosages, you’d need ~100 – 2000mg sublingual ketamine. To achieve the same total exposure, you’d need 430 doses of 100mg ketamine at the low end (for 0.5mM for 24 hours) to 24,000 doses at the high end (10uM for 72 hours) (assuming linearity of dose and concentration, which is probably false).
The following isn’t relevant, but it is interesting: researchers also applied ketamine to some standard laboratory cells (the famous HeLa line, which is descended from cervical cancer) and found it did not speed up cell proliferation- meaning ketamine isn’t an indiscriminate growth factor, but targets certain kinds of cells, including (some?) neurons.
Interval between end of exposure and collection of final metric: 72 hours
Don’t let the title scare you- the toxicity was induced at truly superhuman doses (24 hours at 100x what they call the anesthetic dose, which is already 3x what another paper considered to be the anesthetic dose)
Calibration: the lowest dose of ketamine (20 uM) given corresponds to 40x my estimate for median peak concentration after a 100mg troche.
Chart crimes: that X-axis is neither linear nor any other sensible function.
Chart crimes aside, I’m in love with this graph. By testing a multitude of doses at three different lengths of exposure, it demonstrates 6 things:
Total exposure matters- a constant concentration of 300uM showed negative effects at 12 hours but not 6.
After a threshold is reached, the negative effect of total dose is linear or mildly sublinear.
Peak dosage matters separate from total dose. If that weren’t true, doubling the dose would halve the time it took to show toxicity.
Doubling exposure time is roughly equivalent to increasing dosage by 500uM
At lower doses, longer exposure is correlated with greater cell survival/proliferation. But at higher doses, longer exposure is correlated with lower viability.
The lowest total exposure required to see negative effects is 21,000uM*h, which would require ~17,500 100mg troches- or one every day for 48 years. Before accounting for any repair mechanisms.
The paper spends a great deal of time asking why ketamine is toxic at high doses, focusing on reactive oxidative species (ROS) (the thing that blueberries fight). This suggests that your body’s antioxidant system likely reduces the damage compared to what we see in test tubes. Unfortunately I don’t know how to translate the dosage of Trolox, their anti-oxidant, to blueberries.
Interval between end of exposure and collection of final metric: 60 days (!)
Outcome: synaptic growth
Most of the papers I looked at created their neurons from a stem cell line and then briefly ages This paper stands out for aging the cells for a full 60 days before exposing them to 1 uM ketamine (they also tried hydronorketamine, a byproduct of ketamine metabolism. I’ll be ignoring this, but if you see “HNK” on the graph, that’s what it means).
Here we see that ketamine and its derivative significantly increased the number and length of dendrites (the connections between neurons). It’s possible to have too much of this, but in the moderate amounts shown this should lead to an easier time learning and updating patterns.
Interval between end of exposure and collection of final metric: 0 hours?
This is another paper with a scary title that is not born out by its graphs. It did find evidence of cellular stress (although this is only unequivocal at higher doses), but cell viability was actually higher at lower doses and unchanged at higher doses, and by lower dose I mean “still way more than you’re going to take for depression”
20uM = a higher peak than you will ever experience even under anaesthetic. 20uM for 6 hours has the same cumulative exposure of 42 100mg troches. 100uM for 24 hours has the same cumulative exposure as 142 100mg troches (for the median person)
Capsace 3/7 and ROS luminescence are both measures of oxidative stress (the thing blueberries fight). Cell viability is what it sounds like. There was no statistically significant difference in viability, and eyeballing the graph it looks viability increases with dosage until at least 100uM.
Interval between end of exposure and collection of final metric: 7 days
Exposed cells to neurotoxic cytokines, two forms of ketamine, and two other antidepressants, alone and in combination. The dose of ketamine was 400nM or 0.4uM, which is about 1 100mg sublingual troche.
These graphs are not great.
DCX is a signal of new cell growth (good), CC3 is a sign of cell death (bad), Map2 is a marker for mature neurons (good). In general, whatever the change is between the control and IL-* (the second entry on the X axis) is bad, and you want treatments to go the other way. And what we see is the ketamine treatments are about equivalent to the control. .
Interval between end of exposure and collection of final metric: 0 hours?
(Pink cells are neurons derived from a neurological cancer cell line, Blue cells are liver cells derived from a liver cancer cell line. The red boxes correspond to their estimate of the painkilling, anesthetic, and drug abuse levels of concentration. All conditions were exposed for 24 hours. & means P<0.05; #, P<0.01; $, P<0.001; *, P<0.0001)
This paper found a 20% drop in neuron viability for anesthetic doses of ketamine, and 5% for a painkilling dose (and a milder loss to liver cells). This is compared to an untreated control that lost <1% of cells. They describe this result as “low cytotoxicity” for ketamine. I am confused by this and wonder if they had some pressure to come up with a positive result. On the other hand, the paper’s opening paragraph contains an out-of-left-field accusation that ketamine is a common ingredient in date rape pills, which is irrelevant, makes no sense, and is given no passable justification*, which makes me think at least one author thinks poorly of the chemical. So perhaps I’m merely showing my lack of subject matter expertise, and 20% losses in vitro don’t indicate anything worrisome.
[*They do give a citation, but neither that paper nor the ones it cites offer any reason to believe ketamine is frequently used in sexual assault, just passing mentions. In the anti column we have the facts that ketamine tastes terrible and is poorly absorbed orally, requiring large doses to incapacitate someone. It’s a bad choice to give surreptitiously. Although I wouldn’t doubt that taking ketamine voluntarily makes one more vulnerable.]
Why In Vitro Studies?
Given all their limitations, why did I focus exclusively on in vitro studies? Well, when it comes to studying drug use, you have four choices:
Humans given a controlled dose in a laboratory.
All the studies I found were short-term, often only single use, and measured brain damage with cognitive tests. Combine with a small sample size and you have a measurement apparatus that can only catch very large problems. It’s nice to know those don’t happen (quickly), but I also care about small problems that accumulate over time.
Humans who took large amounts of a substance for a long time on their own initiative.
This group starts out suffering from selection effects and then compounds the problem by applying their can-do attitude towards a wide variety of recreational pharmaceuticals, making it impossible to untangle what damage came from ketamine vs opiates. In the particular case of ketamine, they also do a lot of ketamine, as much as 1-4 grams per day (crudely equivalent to 11-44 uM*h if they take it nasally, and 2-4x that if injected)
I initially thought that contamination of street drugs with harmful substances would also be a big deal. However, a friend directed me to DrugsData.org, a service that until 2024 accepted samples of street drugs and published their chemical makeup. Ketamine was occasionally used as an adulterant, but substances sold under the name ketamine rarely contained much beyond actual ketamine and its byproducts.
Animal studies. I initially dismissed these after I learned that ketamine was not used in isolation in rats and mice (the subjects of almost every animal paper), only in combination with other drugs. However, while writing this up, I learned that this may be due to a difference in use case, rather than a difference in response to ketamine. But when I looked at the available literature there were 6 papers, every one of which gave the rats at least an order of magnitude more ketamine than a person would ever take for depression.
For the curious, here’s why ketamine usage differs in animals and humans:
Ketamine is cheap, both as a substance and because it doesn’t require an anesthesiologist. In some jurisdictions, it doesn’t even require a doctor. Animal work is more cost-conscious and less outcome-conscious, so it’s tilted towards the cheaper anesthetic.
New anesthetics for humans aren’t necessarily tested in animals, so veterinarians have fewer options.
Doctors are very concerned that patients hate their experience not get addicted to medications, and ketamine can be enjoyable (although not physically addictive). Veterinarians are secure that even if your cat trips balls and spends the next six months jonesing, she will not have the power to do anything about it.
Pictured: a cat whose dealer won’t return her texts.
ketamine is rare in that it acts as an anesthetic but not a muscle relaxant. For most surgeries, you want relaxed muscles, so you either combine the ketamine with a muscle relaxant or use another drug entirely. However there are some patients where relaxing muscles is dangerous (generally those with impaired breathing or blood pressure), in which case ketamine is your best option.
Ketamine is unusually well suited for emergency use, because it acts quickly, doesn’t require an anesthesiologist, and can be delivered via shot as well as IV. In those emergencies, you’re not worried about what it can’t do.
All this adds up to a very different usage profile for ketamine for animals vs. humans.
Conclusion
My goal was specifically to examine chronic, low-dose usage of ketamine. Instead, I followed the streetlight effect to one-off prolonged megadoses. I’m delighted at how safe ketamine looks in vitro, but of course, that’s not even in mice.
Thanks
Thanks to the Progress Studies Blog Building Initiative and everyone I’ve talked to for the last three months for feedback on this post. Thanks to my Patreon supporters and the CoFoundation Fellowship for their financial support of my work
This is time consuming work, so if you’d like to support it please check out my Patreon or donate tax-deductibly through Lightcone Infrastructure (mark “for Ketamine research”, minimum donation size $100).


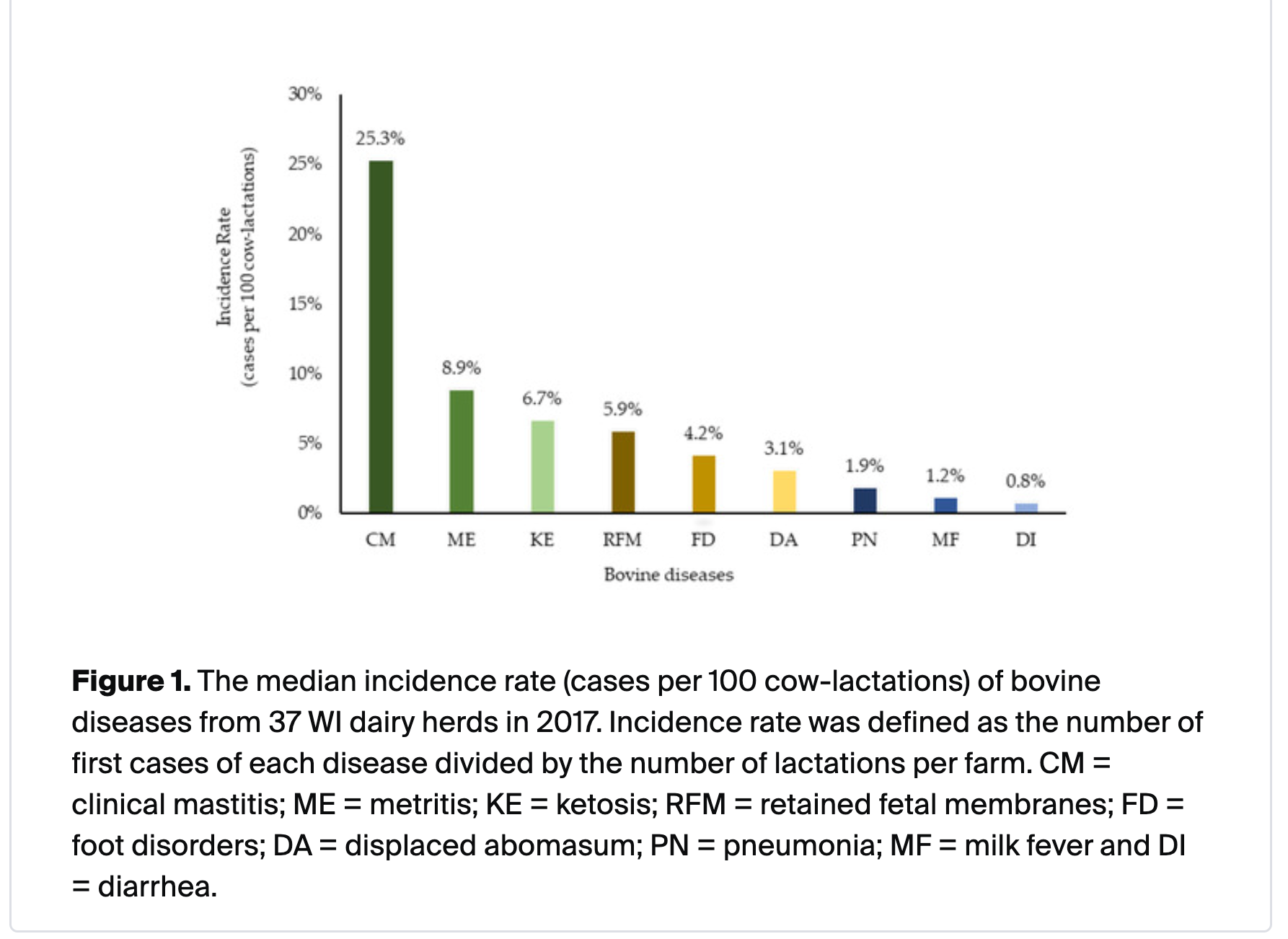
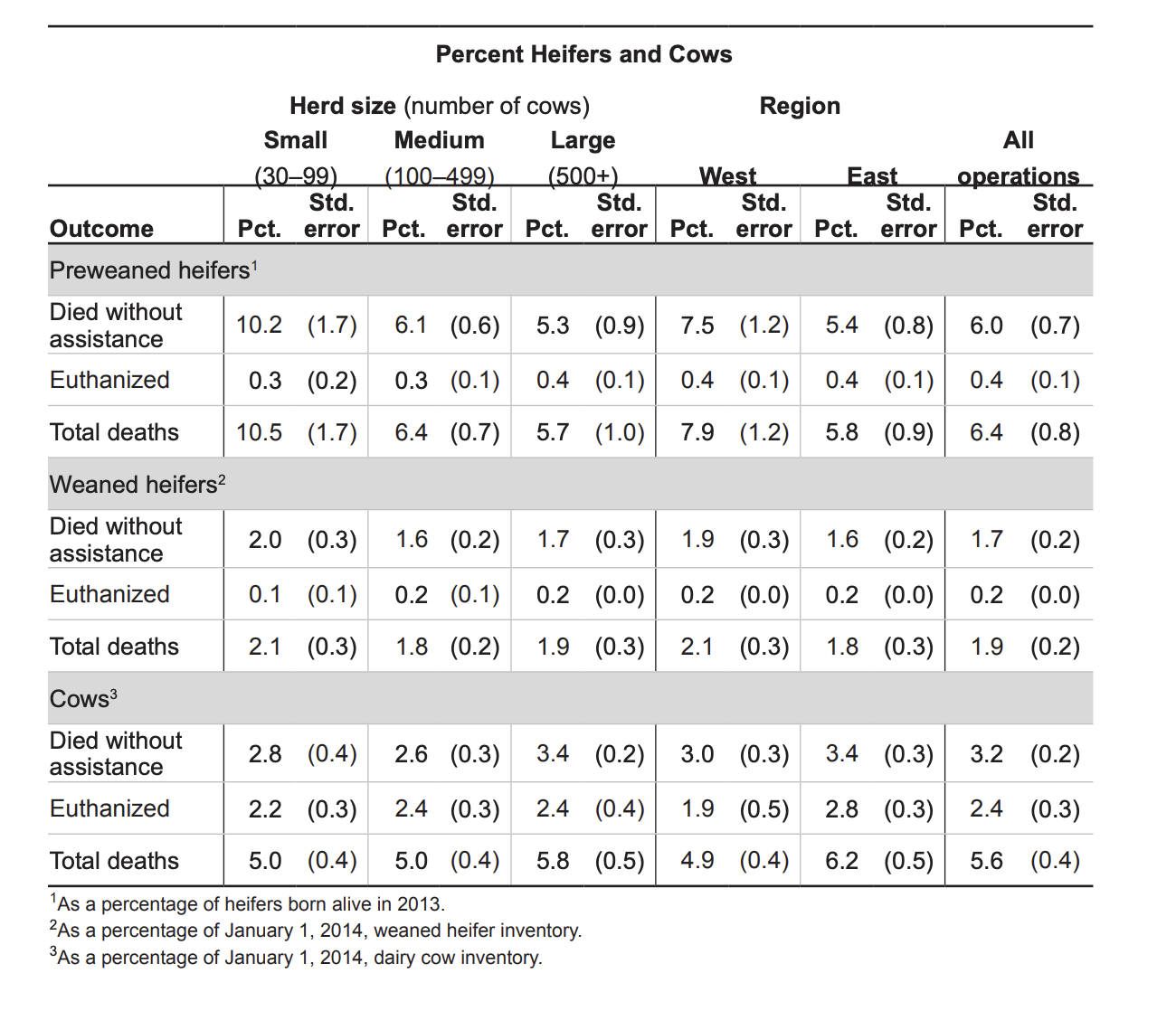


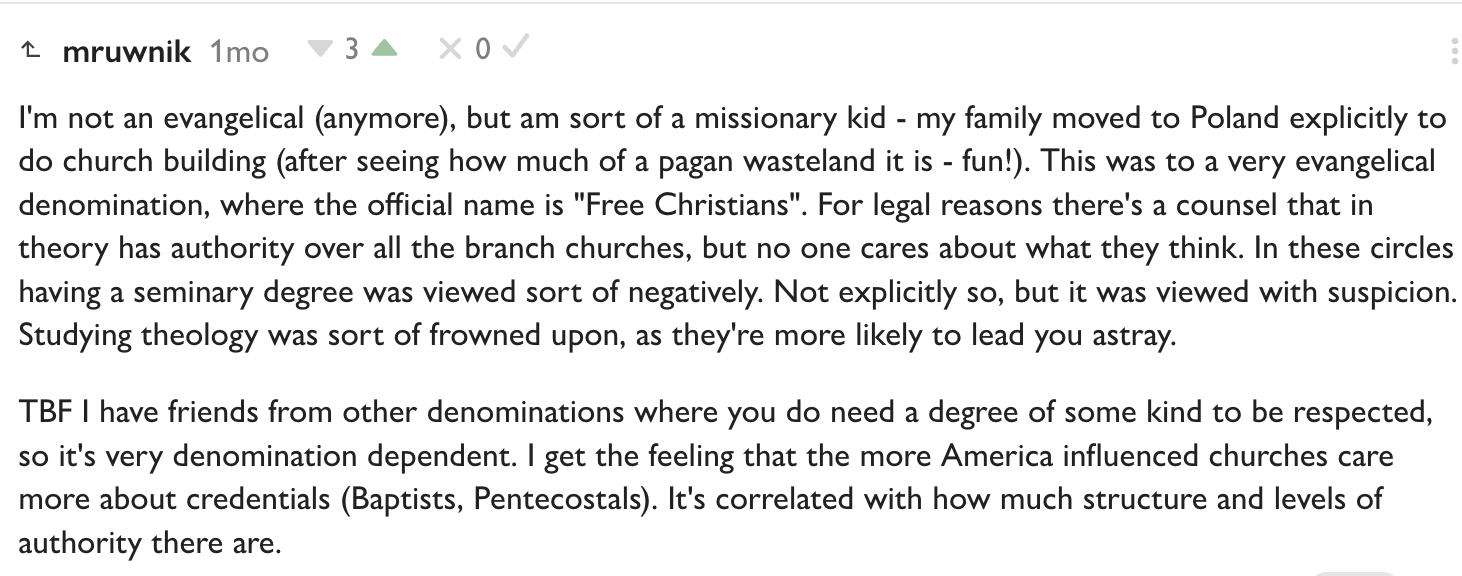
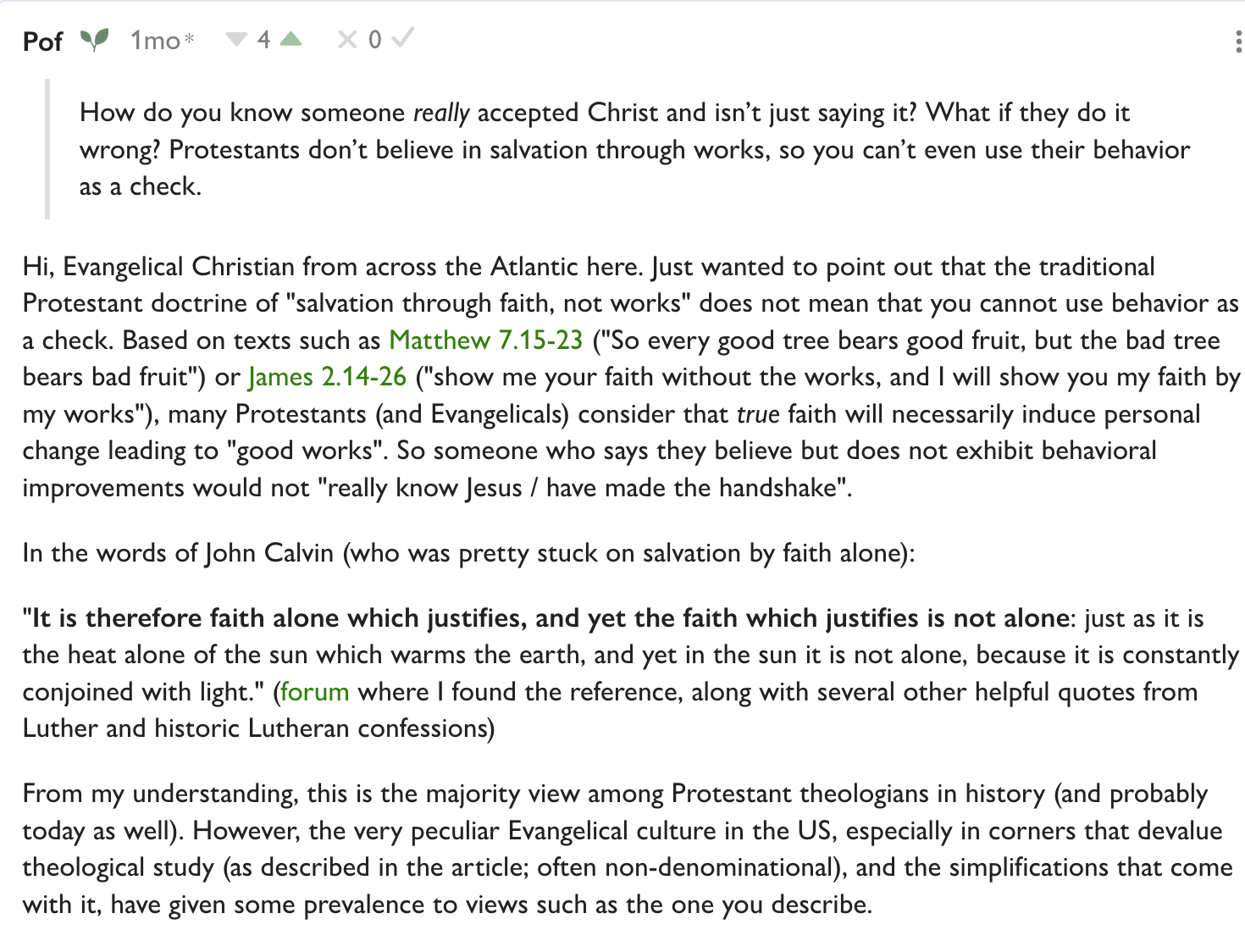
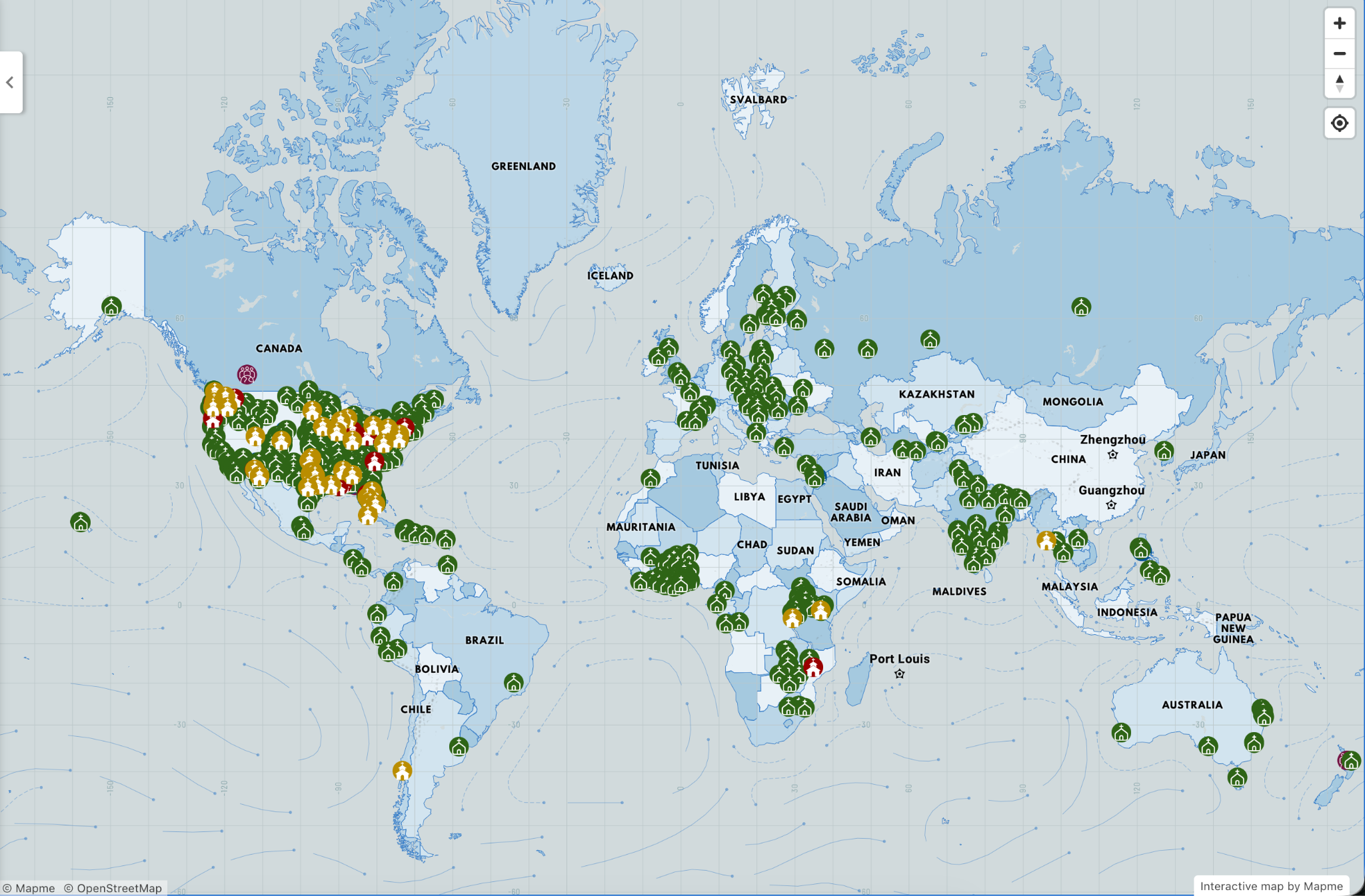
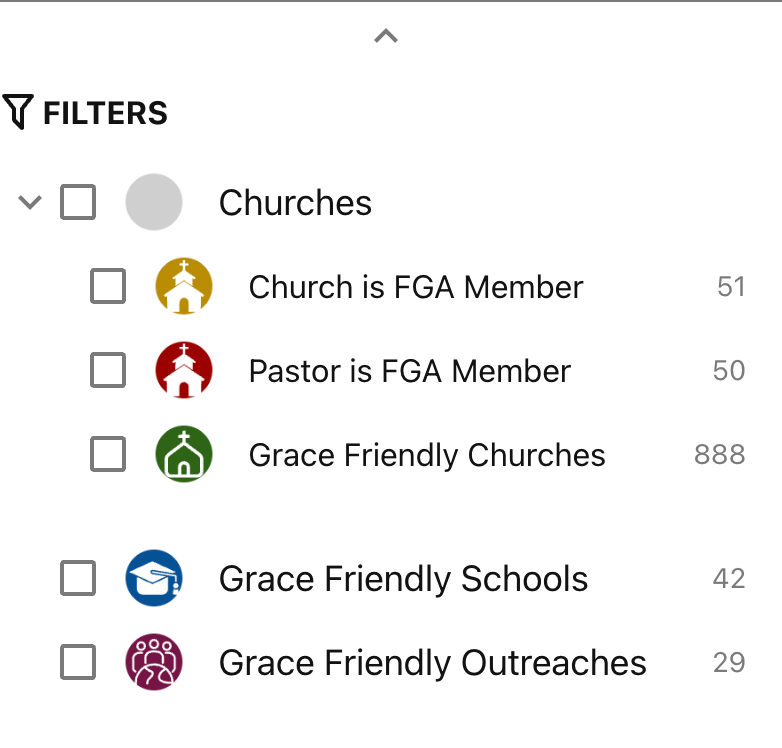


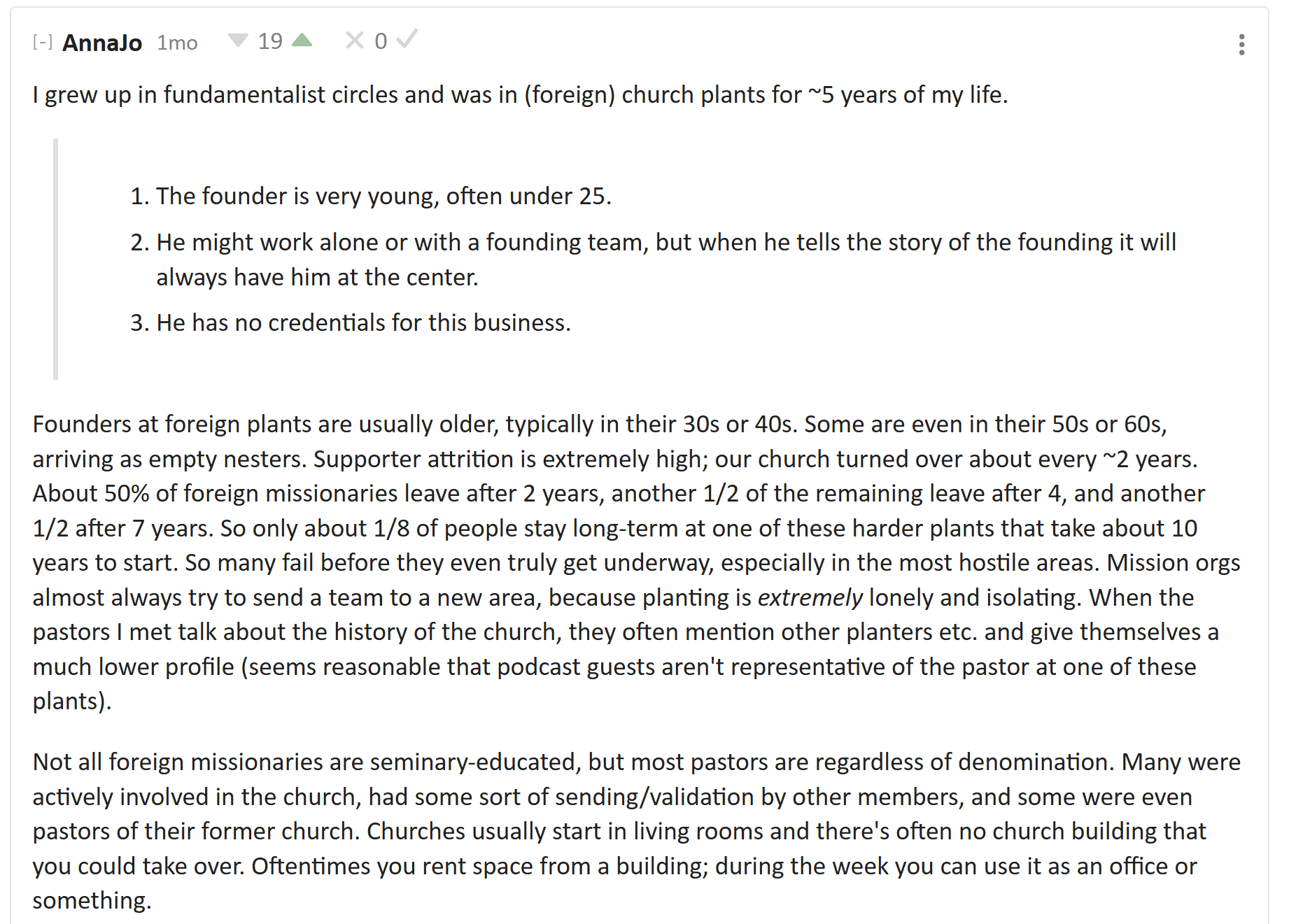




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}