
This document is aimed at subcontractors doing medical research for me. I am sharing it in the hope it is more broadly useful, but have made no attempts to make it more widely accessible.
Intro
Guesstimate is a tool I have found quite useful in my work, especially in making medical estimates in environments of high uncertainty. It’s not just that it makes it easy to do calculations incorporating many sources of data; guesstimate renders your thinking much more legible to readers, who can then more productively argue with you about your conclusions.
The basis of guesstimate is breaking down a question you want an answer to (such as “what is the chance of long covid?”) into subquestions that can be tackled independently. Questions can have numerical answers in the form of a single number, a range, or a formula that references other questions. This allows you to highlight areas of relative certainty and relative uncertainty, to experiment with the importance of different assumptions, and for readers to play with your model and identify differences of opinion while incorporating the parts of your work they agree with.
Basics
If you’re not already familiar with guesstimate, please watch this video, which references this model. The video goes over two toy questions to help you familiarize yourself with the interface.
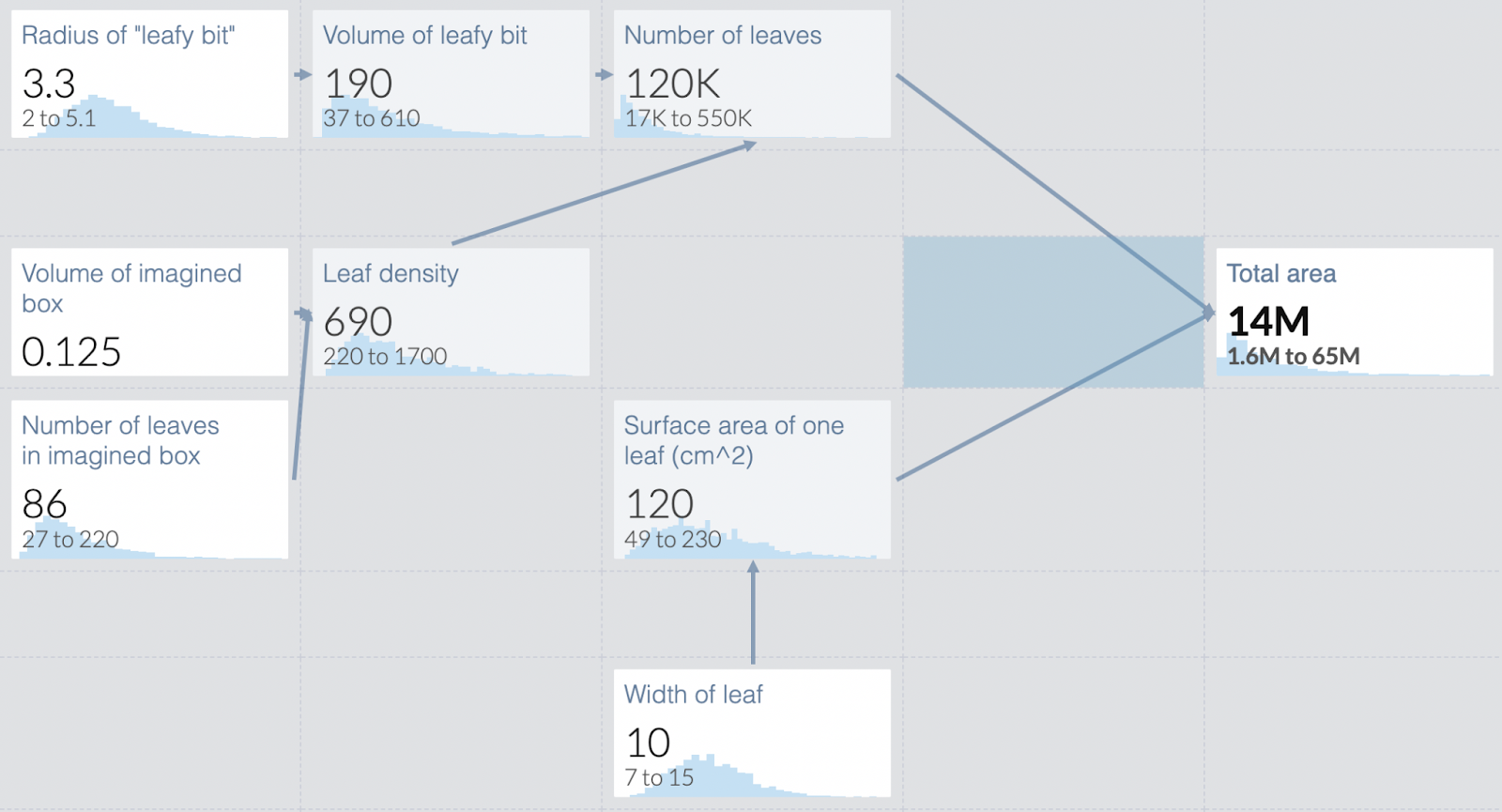
The Algorithm
The following is my basic algorithm for medical questions:
- Formalize the question you want an answer to. e.g. what is the risk to me of long covid?
- Break that question down into subquestions. The appropriate subquestion varies based on what data is available, and your idea of the correct subquestions is likely to change as you work.
- When I was studying long covid last year, I broke it into the following subquestions
- What is the risk with baseline covid?
- What is the vaccine risk modifier?
- What is the strain risk modifier?
- What’s the risk modifier for a given individual?
- When I was studying long covid last year, I broke it into the following subquestions
- In guesstimate, wire the questions together. For example, if you wanted to know your risk of hospitalization when newly vaccinated in May 2021, you might multiply the former hospitalization rate times a vaccine modifier. If you don’t know how to do that in guesstimate, watch the video above, it demonstrates it in a lot of detail.
- Use literature to fill in answers to subquestions as best you can. Unless the data is very good, these probably include giving ranges and making your best guess as to the shape of the distribution of values.
- Provide citations for where you got those numbers. This can be done in the guesstimate commenting interface, but that’s quite clunky. Sometimes it’s better to have a separate document where you lay out your reasoning.
- The reader should be able to go from a particular node in the guesstimate to your reasoning for that node with as little effort as possible.
- Guesstimate will use log-normal distribution by default, but you can change it to uniform or normal if you believe that represents reality better.
- Sometimes there are questions literature literally can’t answer, or aren’t worth your time to research rigorously. Make your best guess, and call it out as a separate variable so people can identify it and apply their own best guess.
- This includes value judgments, like the value of a day in lockdown relative to a normal day, or how much one hates being sick.
- Or the 5-year recovery rate from long covid- no one can literally measure it, and while you could guess from other diseases, the additional precision isn’t necessarily worth the effort.
- Final product is both the guesstimate model and a document writing up your sources and reasoning.
Example: Trading off air quality and covid.
The final model is available here.
Every year California gets forest fires big enough to damage air quality even if you are quite far away, which pushes people indoors. This was mostly okay until covid, which made being indoors costly in various ways too. So how do we trade those off? I was particularly interested in trading off outdoor exercise vs the gym (and if both had been too awful I might have rethought my stance on how boring and unpleasant working out in my tiny apartment is).
What I want to know is the QALY hit from 10 minutes outdoors vs 10 minutes indoors. This depends a lot on the exact air quality and covid details for that particular day, so we’ll need to have variables for that.
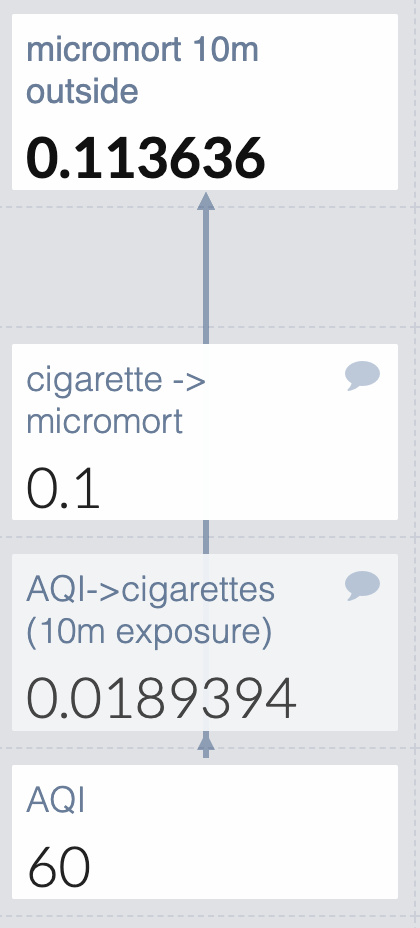
For air quality, I used the calculations from this website to turn AQI into cigarettes. I found a cigarette -> micromort converter faster than cigarette -> QALY so I’m just going to use that. This is fine as long as covid and air quality have the same QALY:micromort ratio (unlikely) or if the final answer is clear enough that even large changes in the ratio would not change our decision (judgment call).
For both values that use outside data I leave a comment with the source, which gives them a comment icon in the upper right corner.
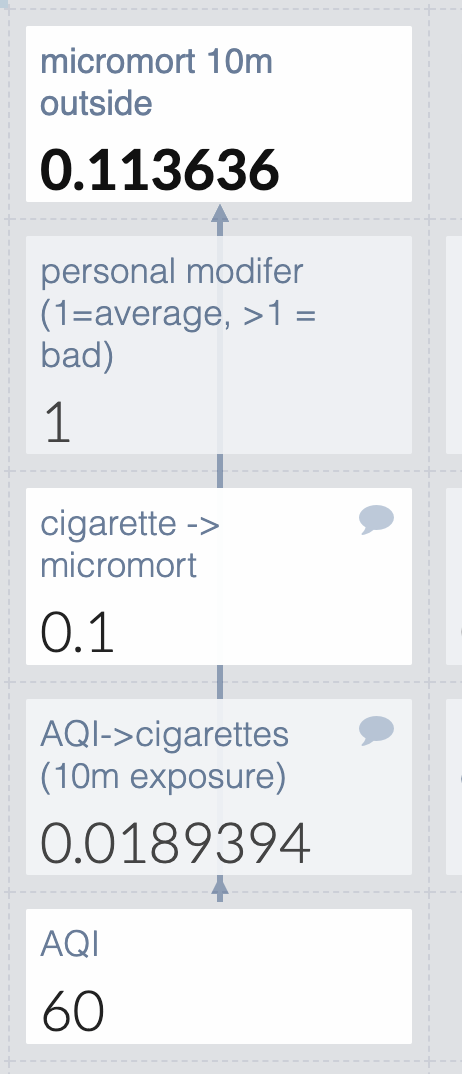
But some people are more susceptible than others due to things like asthma or cancer, so I’ll add a personal modifier. I’m not attempting to define this well: people with lung issues can make their best guess. They can’t read my mind though, so I’ll make it clear that 1=average and which direction is bad.
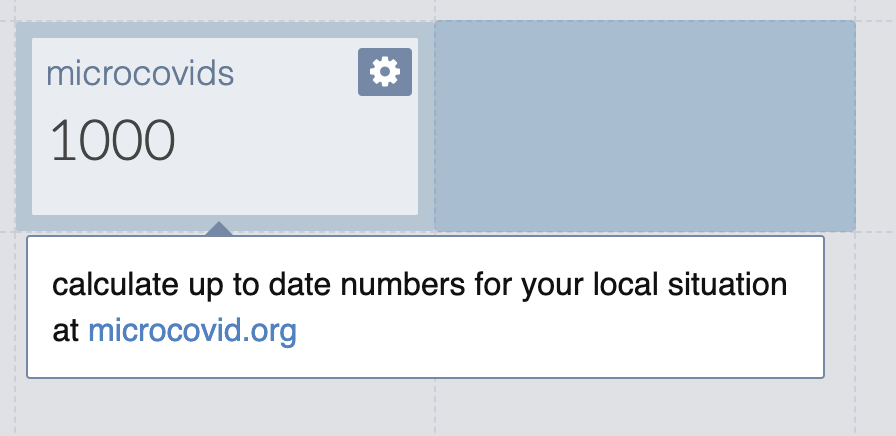
Okay how about 10 minutes inside? That depends a lot on local conditions. I could embed those all in my guesstimate, or I could punt to microcovid. I’m not sure if microcovid is still being maintained but I’m very sure I don’t feel like creating new numbers right now, so we’ll just do that. I add a comment with basic instructions.
How about microcovids to micromorts? The first source I found said 10k per infection, which is a suspiciously round number but it will do for now. I device the micromorts by 1 million, since each microcovid is 1/1,000,000 chance of catching covid.

They could just guess their personal risk modifier like they do for covid, or they could use this (pre-vaccine, pre-variant) covid risk calculator from the Economist, so I’ll leave a note for that.
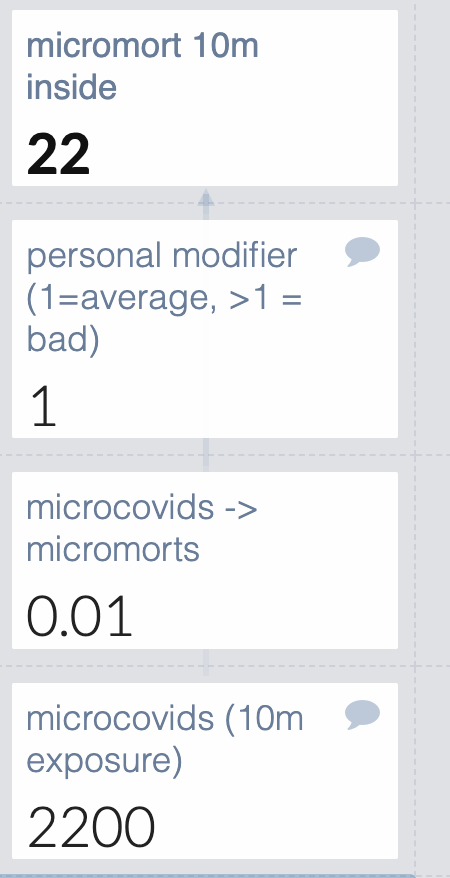
But wait- there are two calculations happening in the microcovids -> micromorts cell, which makes it hard to edit if you disagree with me about the risk of covid. I’m going to move the /1,000,000 to the top cell so it’s easy to edit.

But the risk of catching covid outside isn’t zero. Microcovid says outdoors has 1/20th the risk. I’m very sure that’s out of date but don’t know the new number so I’ll make something up and list it separately so it’s easy to edit
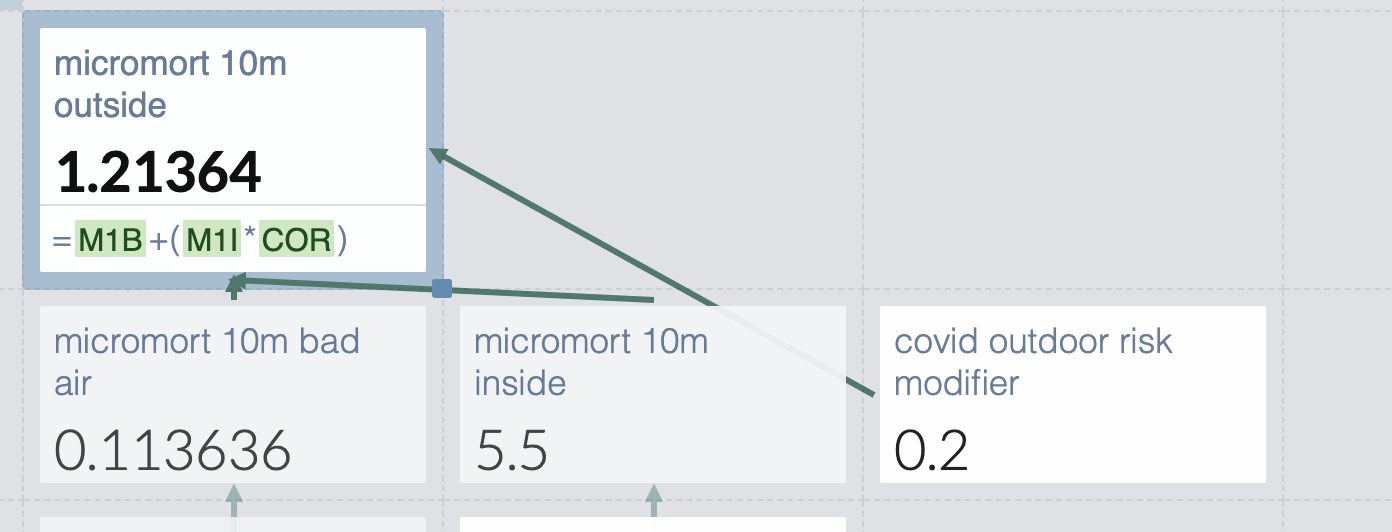
But wait- I’m not necessarily with the same people indoors and out. The general density of people is comparable if I’m deciding to throw a party inside or outside, but not if I’m deciding to exercise outdoors or at a gym. So I should make that toggleable.
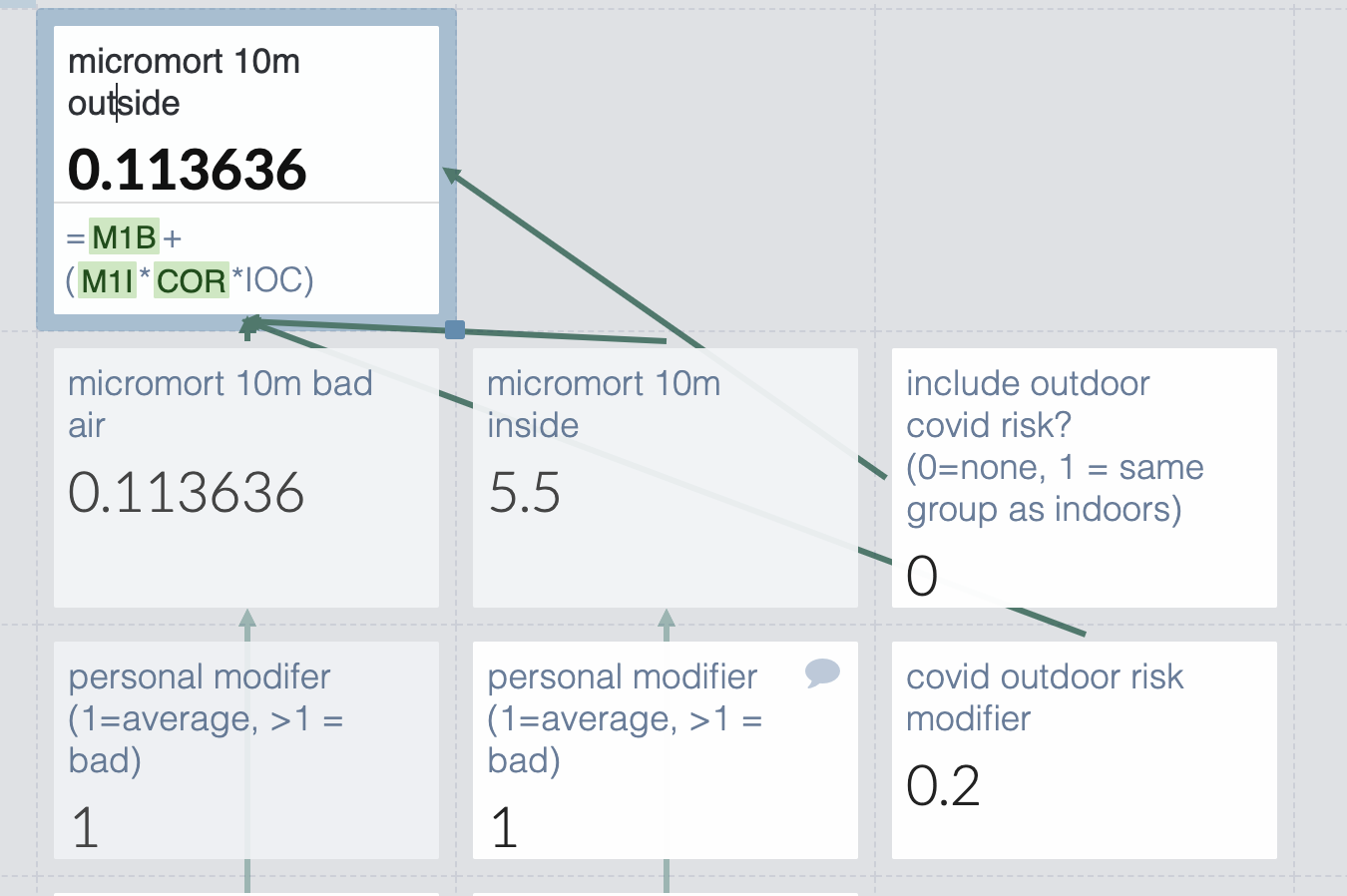
Eh, I’m still uncomfortable with that completely made up outdoor risk modifier. Let’s make it a range so we can see the scope of possible risks. Note that this only matters if we’re meeting people outdoors, which seems correct.
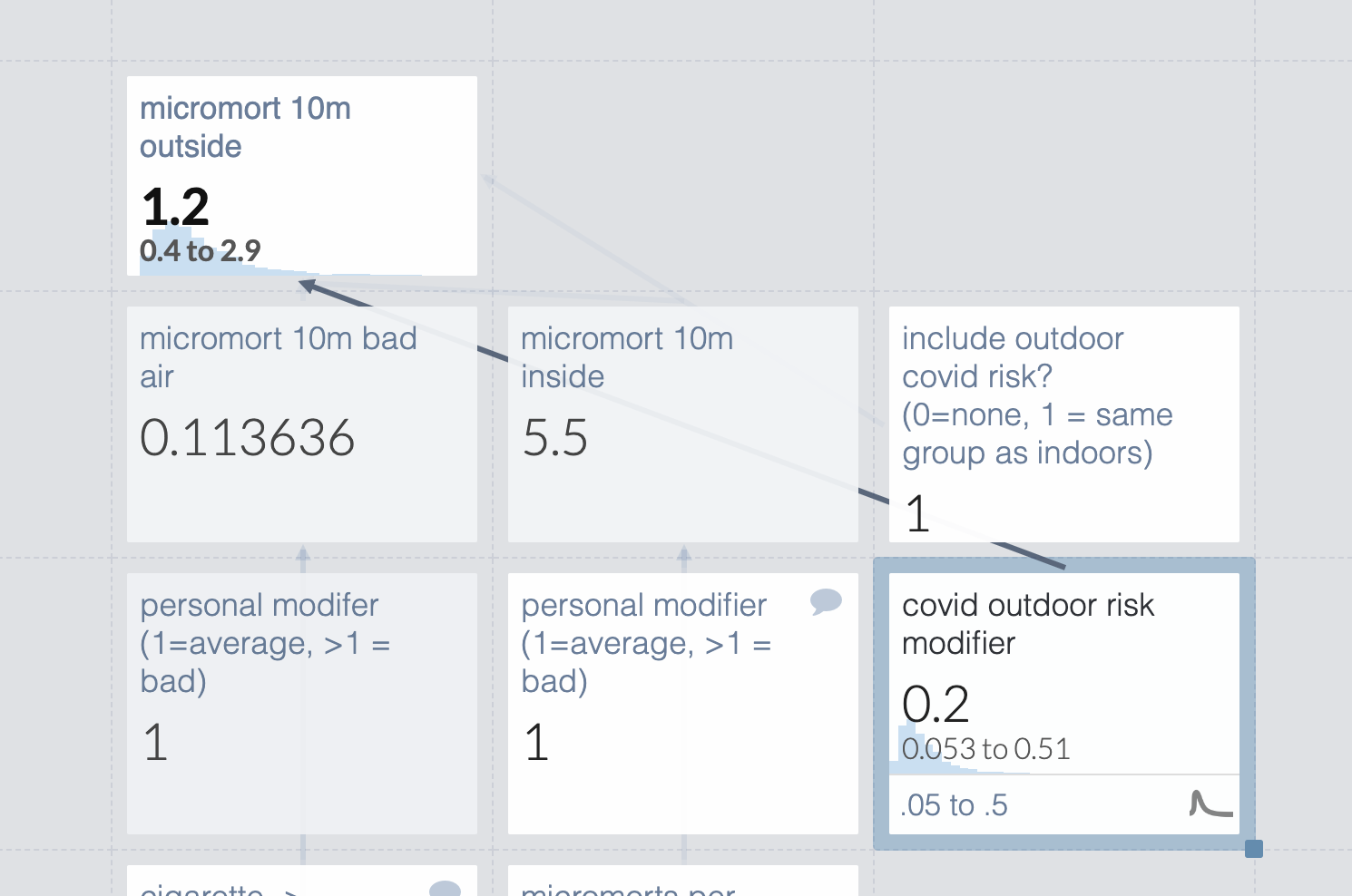
But that used guesstimate’s default probability distribution (log normal). I don’t see a reason probability density would concentrate at the low end of the distribution, so I switch it to normal.
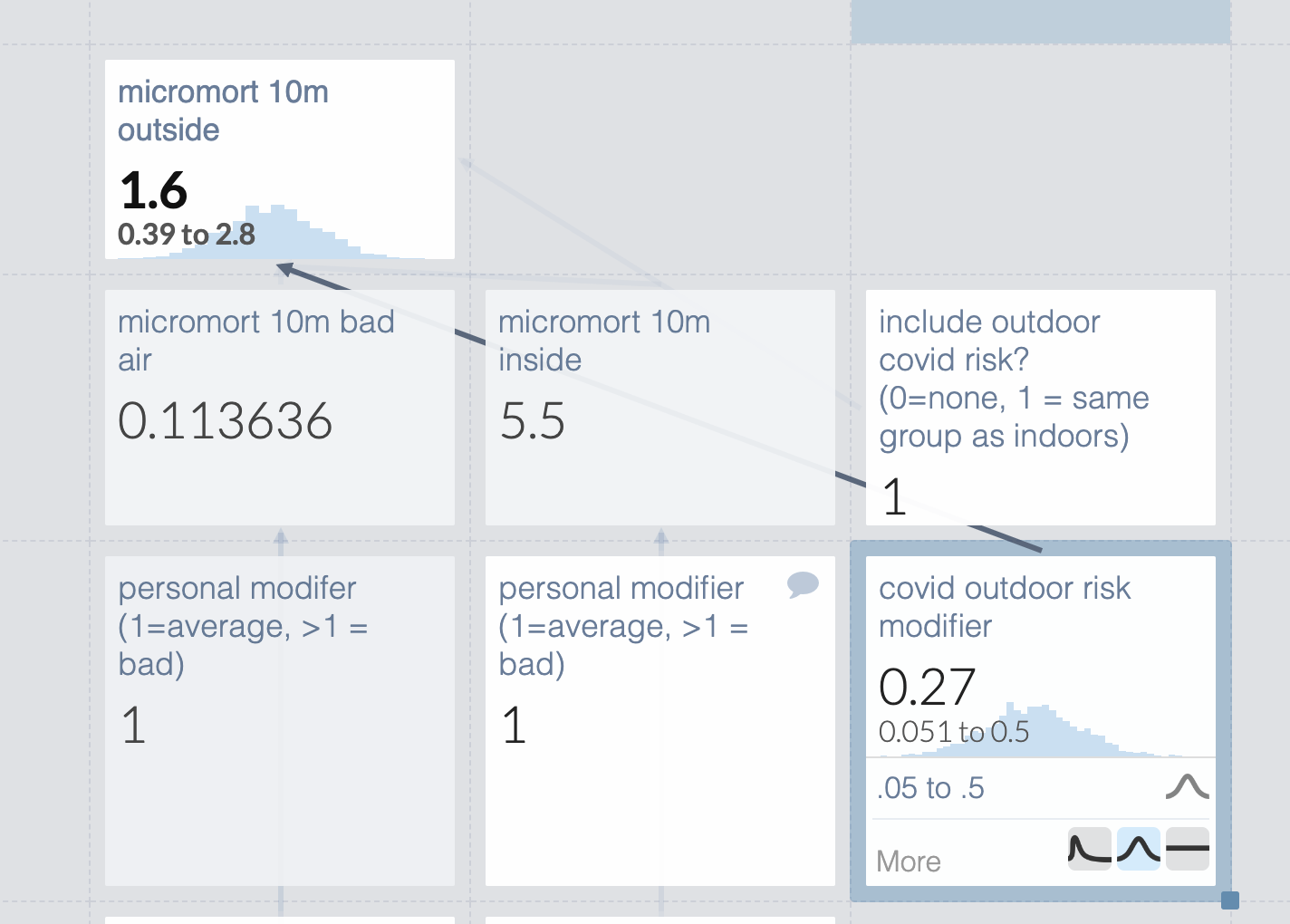
Turns out to make very little difference in practice.
There are still a few problems here. Some of the numbers are more or less made up, and others have sources but I’ve done no work to verify them, which is almost as bad.
But unless the numbers are very off, covid is a full order of magnitude riskier than air pollution for the scenarios I picked. This makes me disinclined to spend a bunch of time tracking down better numbers.
Full list of limitations:
- Only looks at micromorts, not QALYs
- Individual adjustment basically made up, especially for pollution
- Several numbers completely made up
- Didn’t check any of my sources
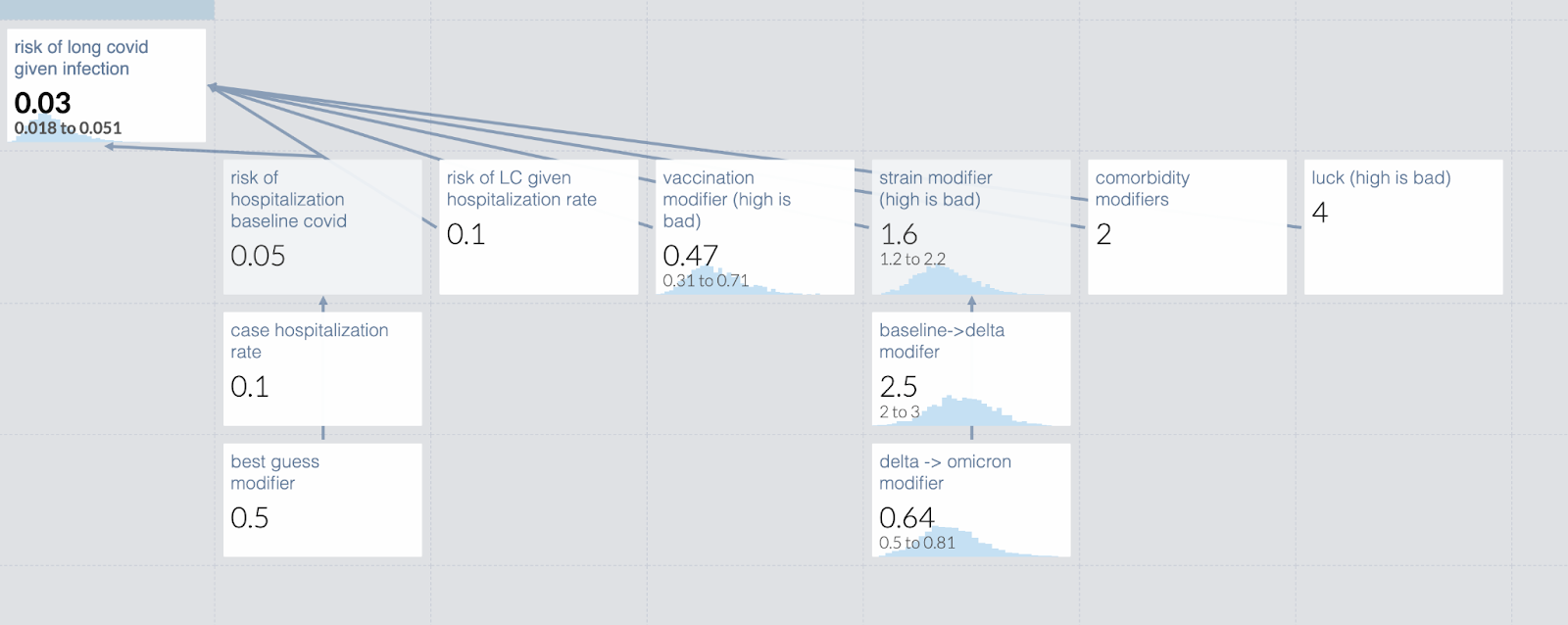
Example: Individual’s chance of long covid given infection
This will be based on my post last year, Long covid is not necessarily your biggest problem, with some modification for pedagogical purposes. And made up numbers instead of real ones because the specific numbers have long been eclipsed by new data and strains. The final model is available here.
Step one is to break your questions into subquestions. When I made this model a year ago, we only had data for baseline covid in unvaccinated people. Everyone wanted to know how vaccinations and the new strain would affect things.
My first question was “can we predict long covid from acute covid?” I dug into the data and concluded “Yes”, the risk of long covid seemed to be very well correlated with acute severity. This informed the shape of the model but not any particular values. Some people disagreed with me, and they would make a very different model.
Once I made that determination, the model was pretty easy to create: It looked like [risk of hospitalization with baseline covid] * [risk of long covid given hospitalization rate] * [vaccination risk modifier] * [strain hospitalization modifier] * [personal risk modifier]. Note that the model I’m creating here does not perfectly match the one created last year; I’ve modified it to be a better teaching example.
The risk of hospitalization is easy to establish unless you start including undetected/asymptomatic cases. This has become a bigger deal as home tests became more available and mild cases became more common, since government statistics are missing more mild or asymptomatic cases. So in my calculation, I broke down the risk of hospitalization given covid to the known case hospitalization rate and then inserted a separate term based on my estimate of the number of uncaught cases. In the original post I chose some example people and used base estimates for them from the Economist data. In this model, I made something up.
Honestly, I don’t remember how I calculated the risk of long covid given the hospitalization rate. It was very complicated and a long time ago. This is why I write companion documents to explain my reasoning.
Vaccination modifier was quite easy, every scientist was eager to tell us that. However, there are now questions about vaccines waning over time, and an individual’s protection level is likely to vary. Because of that, in this test model I have entered a range of vaccine efficacies, rather than a point estimate. An individual who knew how recently they were vaccinated might choose to collapse that down.
Similarly, strain hospitalization modifiers take some time to assess, but are eventually straightforwardly available. Your estimate early in a new strain will probably have a much wider confidence interval than your estimate late in the same wave.
By definition, I can’t set the personal risk modifier for every person looking at the model. I suggested people get a more accurate estimate of their personal risk using the Economist calculator, and then enter that in the model.
Lastly, there is a factor I called “are you feeling lucky?”. Some people don’t have anything diagnosable but know they get every cold twice; other people could get bitten by a plague rat with no ill effects. This is even more impossible to provide for an individual but is in fact pretty important for an individual’s risk assessment, so I included it as a term in the model. Individuals using the model can set it as they see fit, including to 1 if they don’t want to think about it.
When I put this together, I get this guesstimate. [#TODO screenshot]. Remember the numbers are completely made up. If you follow the link you can play around with it yourself, but your changes will not be saved. If anyone wants to update my model with modern strains and vaccine efficacy, I would be delighted.
Tips and Tricks
I’m undoubtedly missing many, so please comment with your own and I’ll update or create a new version later.
When working with modifiers, it’s easy to forget whether a large number is good or bad, and what the acceptable range is. It can be good to mark them with “0 to 1, higher is less risky”, or “between 0 and 1 = less risk, >1 = more risk”
If you enter a range, the default distribution is log-normal. If you want something different, change it.
The formulas in the cells can get almost arbitrarily complicated, although it’s often not worth it.
No, seriously, write out your sources and reasoning somewhere else because you will come back in six months and not remember what the hell you were thinking. Guesstimate is less a tool for holding your entire model and more a tool for forcing you to make your model explicit.
Separate judgment calls from empirical data, even if you’re really sure you are right.
Acknowledgements
Thanks to Ozzie Gooen and his team for creating Guesstimate.
Thanks to the FTX Regrant program and a shy regrantor for funding this work.
