
Tl;dr: I created a dataset of US counties’ water contamination and obesity levels. So far I have failed to find anything really interesting with it, but maybe you will. If you are interested you can download the dataset here. Be warned every spreadsheet program will choke on it; you definitely need to be use statistical programming.

Many of you have read Slime Mold Time Mold’s series on the hypothesis that environmental contaminants are driving weight gain. I haven’t done a deep dive on their work, but their lit review is certainly suggestive.
SMTM did some original analysis by looking at obesity levels by state, but this is pretty hopeless. They’re using average altitude by state as a proxy for water purity for the entire state, and then correlating that with the state’s % resident obesity. Water contamination does seem negatively correlated with its altitude, and its altitude is correlated with an end-user’s altitude, and that end user’s altitude is correlated with their average state altitude… but I think that’s too many steps removed with too much noise at each step. So the aggregation by state is basically meaningless, except for showing us Colorado is weird.
So I dug up a better data set, which had contamination levels for almost every water system in the country, accessible by zip code, and another one that had obesity prevalence by county. I combined these into a single spreadsheet and did some very basic statistical analysis on them to look for correlations.
Some caveats before we start:
- The dataset looks reasonable to me, but I haven’t examined it exhaustively and don’t know where the holes are.
- Slime Mold Time Mold’s top contender for environmental contagion is lithium. While technically present in the database, litium had five entries so I ignored it. I haven’t investigated but my guess is no one tests for lithium.
- It’s rare, but some zip codes have multiple water suppliers, and the spreadsheet treats them as two separate entities that coincidentally have the same obesity prevalence.
- I’ve made no attempt to back out basic confounding variables like income or age.
- “% obese” is a much worse metric than average BMI, which is itself a much worse metric than % body fat.
- None of those metrics would catch if a contaminant makes some people very fat while making others thin ( SMTM thinks paradoxical effects are a big deal, so this is a major gap for testing their model).
- Correlation still does not equal causation.
The correlations (for contaminants with >10k entries):
| Contaminant | Correlation | # Samples |
| Nitrate | -0.039 | 21430 |
| Total haloacetic acids (HAAs) | 0.055 | 14666 |
| Chloroform | 0.046 | 15065 |
| Barium (total) | 0.040 | 17929 |
| Total trihalomethanes (TTHMs) | 0.117 | 21184 |
| Copper | -0.002 | 17113 |
| Dibromochloromethane | 0.080 | 13856 |
| Nitrate & nitrite | 0.035 | 11902 |
| Bromodichloromethane | 0.079 | 14238 |
| Lead (total) | -0.006 | 13031 |
| Dichloroacetic acid | -0.003 | 10159 |
Of these, the only one that looks interesting is trihalomethanes, a chemical group that includes chloroform. Here’s the graph:
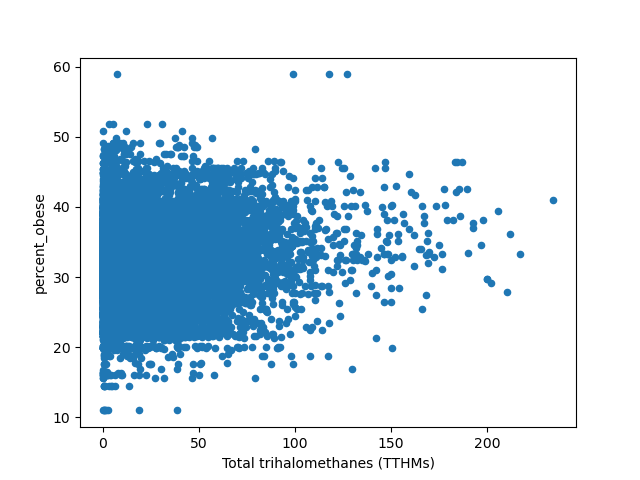
Visually this looks like the floor is rising much faster than the ceiling, but in a conversation on twitter SMTM suggested that’s an artifact of the biviariate distribution, it disappears if you look at log normal.
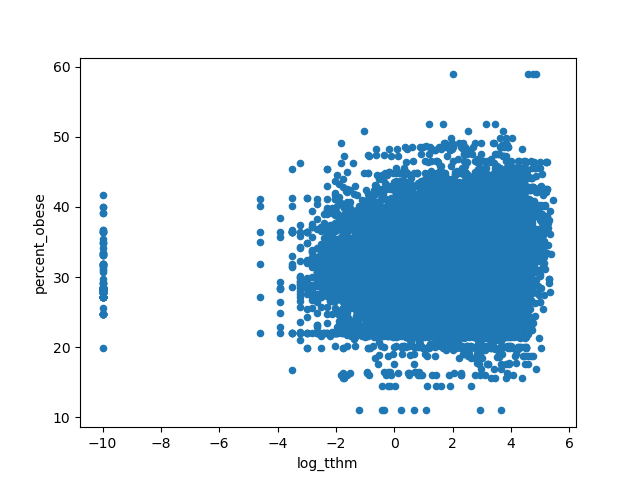
Very casual googling suggests that TTHMs are definitely bad for pregnancy in sufficient quantities, and are maybe in a complicated relationship with Type 2 diabetes, but no slam dunks.
This is about as far as I’ve had time to get. My conclusions alas are not very actionable, but maybe someone else can do something interesting with the data.
Thanks to Austin Chen for zipping the two data sets together, Daniel Filan for doing additional data processing and statistical analysis, and my Patreon patrons for supporting this research.

I’m very interested in county-level data for all sorts of things but haven’t found any sources that map it or allow some sort of aggregation and filtering. Any suggestions?